Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- □ Pourquoi votre site n'apparaît-il pas dans Google : indexation ou ranking ?
- □ Pourquoi Google pousse-t-il Search Console pour diagnostiquer l'indexation ?
- □ L'URL Inspection Tool de Search Console remplace-t-il vraiment le test d'indexation manuel ?
- □ Le rapport d'indexation de la Search Console suffit-il vraiment à diagnostiquer vos problèmes d'indexation ?
- □ Faut-il vraiment chercher à indexer 100% de ses pages ?
- □ Pourquoi Google indexe-t-il toujours la page d'accueil en premier sur un nouveau site ?
- □ Pourquoi la page d'accueil de votre nouveau site ne s'indexe-t-elle pas ?
- □ Votre site est-il vraiment absent de l'index Google ou juste victime de la canonicalisation ?
- □ Hreflang fausse-t-il vos rapports d'indexation dans Search Console ?
- □ Pourquoi vos pages 'site en construction' ne seront jamais indexées par Google ?
- □ Pourquoi certaines pages s'indexent en quelques secondes et d'autres jamais ?
- □ Google peut-il encore indexer l'intégralité du web ?
- □ Google applique-t-il vraiment un quota d'indexation par site ?
- □ Faut-il supprimer l'ancien contenu pour améliorer l'indexation du nouveau ?
- □ Faut-il vraiment utiliser la fonction 'Demander une indexation' de la Search Console ?
- □ L'opérateur site: est-il vraiment fiable pour mesurer l'indexation de votre site ?
- □ Comment exploiter vraiment l'opérateur site: au-delà de la simple vérification d'indexation ?
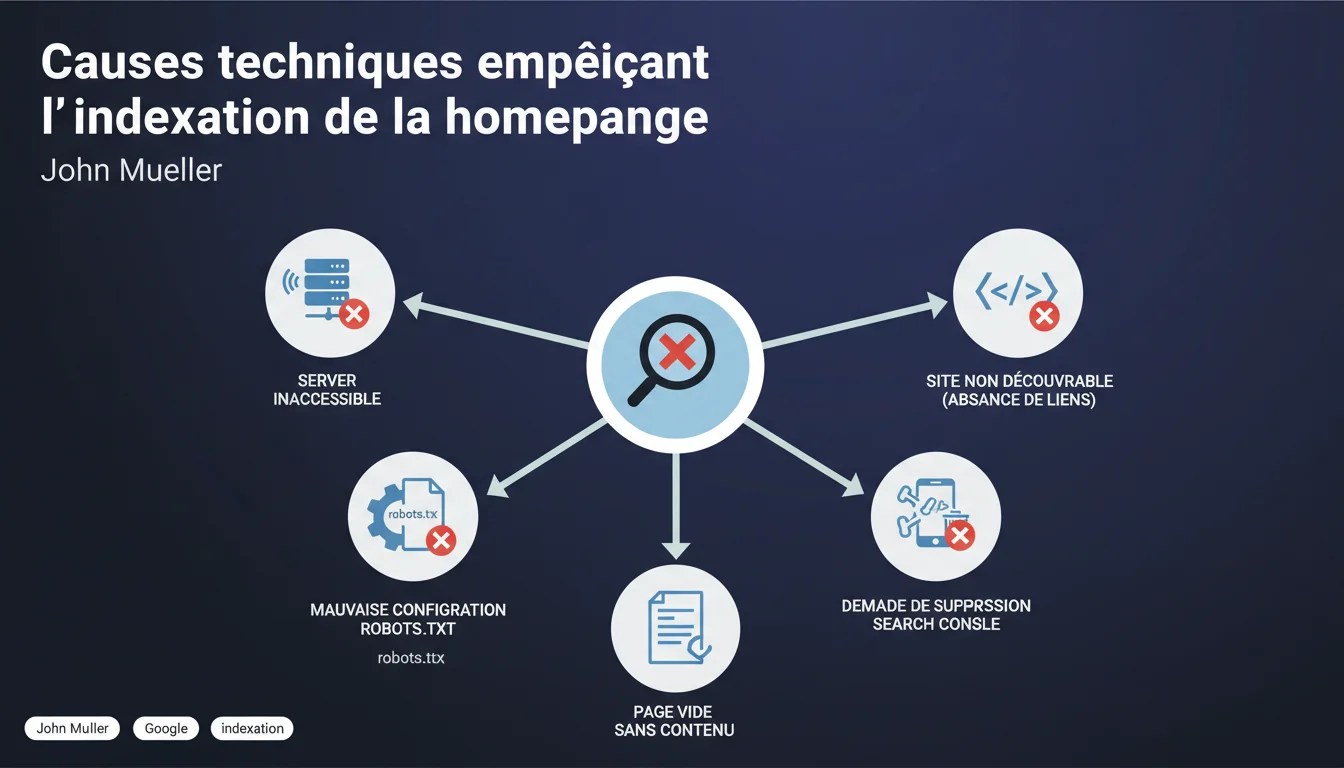
John Mueller liste les causes techniques qui bloquent l'indexation d'une homepage : serveur inaccessible, robots.txt mal configuré, balise noindex, page vide ou invisible pour Googlebot, site isolé sans liens entrants, ou demande de suppression via Search Console. Six obstacles récurrents qui, une fois identifiés, se règlent souvent en quelques minutes — mais qui peuvent paralyser un site pendant des semaines si on ne sait pas où chercher.
Ce qu'il faut comprendre
Quand une homepage refuse de s'indexer, la panique s'installe vite. Pourtant, Mueller rappelle ici que les causes sont souvent prosaïques et se regroupent en six familles distinctes.
Comprendre ces blocages, c'est aussi comprendre la logique du crawl et de l'indexation : Google ne devine pas, il applique des règles strictes.
Quels sont les obstacles techniques les plus fréquents ?
Le premier, souvent sous-estimé : le serveur inaccessible. Si Googlebot ne peut pas joindre l'URL, rien ne se passe. Timeouts répétés, erreurs 5xx persistantes, IP bloquée côté firewall — autant de scénarios banals mais redoutables.
Ensuite, le robots.txt. Une directive Disallow: / ou une règle mal placée suffit à tout bloquer. Et non, Google n'enverra pas d'email pour signaler l'erreur.
Troisième cas : la balise noindex active, parfois oubliée après un lancement ou héritée d'un environnement de staging mal nettoyé. Elle se cache dans le <head> ou dans l'en-tête HTTP — deux endroits distincts à vérifier.
Une page peut-elle être vide aux yeux de Google sans l'être pour l'utilisateur ?
Absolument. Une page sans contenu indexable peut afficher des images, du JavaScript, des iframes — mais si aucun texte HTML n'est présent au moment du crawl initial, Google n'a rien à se mettre sous la dent.
Les sites 100% JavaScript en rendu côté client (CSR) en font souvent les frais. Si le serveur renvoie un DOM quasi-vide et que le contenu ne s'affiche qu'après exécution de scripts, Googlebot peut passer à côté lors de la première passe — même si un second rendu finit par arriver.
Que signifie « site non découvrable » dans ce contexte ?
Un site sans liens entrants est invisible. Google découvre les URL par crawl de liens — pas par télépathie.
Si aucun site externe ne pointe vers votre homepage, que vous n'avez pas soumis de sitemap XML, et que Google n'avait jamais crawlé votre domaine auparavant, votre site reste hors radar. C'est rare pour une homepage, mais ça arrive sur des domaines neufs ou des migrations mal pilotées.
- Six causes principales : serveur, robots.txt, noindex, contenu vide, absence de liens, suppression manuelle.
- Chaque cause a son diagnostic propre — aucune solution universelle.
- La plupart des blocages se détectent via Search Console, les outils de crawl ou un simple
curl. - Google n'avertit jamais d'une erreur de configuration — c'est au SEO de vérifier.
Avis d'un expert SEO
Mueller dresse un inventaire complet et peu surprenant. Ces six points sont enseignés dès les bases du SEO — mais leur récurrence prouve qu'ils restent des angles morts fréquents, y compris chez des équipes expérimentées.
Ce qui manque ici : la hiérarchisation. Tous ces problèmes n'ont pas la même probabilité ni la même gravité. Un robots.txt défaillant ou une balise noindex oubliée se rencontrent bien plus souvent qu'une homepage réellement vide ou un site totalement isolé.
Cette liste est-elle exhaustive ou masque-t-elle d'autres cas ?
Elle couvre l'essentiel, mais pas tout. Par exemple : les redirections en chaîne mal gérées, les canonicals pointant ailleurs, ou encore un serveur qui renvoie un statut 200 pour une page 404 soft (erreur fantôme invisible pour les outils classiques).
Autre cas non mentionné : la pénalité manuelle. Si Google a appliqué une action manuelle sur le site, l'indexation peut être bloquée ou fortement ralentie — et Search Console affiche alors une notification spécifique. [A vérifier] si cette déclaration inclut implicitement ce cas sous « demande de suppression ».
Enfin, Mueller ne dit rien sur les délais d'indexation normaux. Combien de temps attendre avant de diagnostiquer un problème ? 48 heures ? Une semaine ? Deux ? Aucune indication chiffrée — ce qui laisse place à l'interprétation.
Quelles erreurs d'interprétation faut-il éviter ?
Première erreur : croire qu'une homepage doit s'indexer instantanément. Sur un domaine neuf sans autorité ni backlinks, l'indexation peut prendre du temps même sans obstacle technique.
Deuxième erreur : confondre crawl et indexation. Google peut crawler une page sans l'indexer — par choix éditorial, qualité insuffisante, ou duplication perçue. Les logs serveur montrent le passage de Googlebot, mais l'URL reste absente de l'index.
Impact pratique et recommandations
Comment diagnostiquer le blocage de l'indexation d'une homepage ?
Première étape : Search Console. Utilisez l'outil d'inspection d'URL sur votre homepage. Si Google indique « URL non indexée », le rapport détaille la raison exacte — balise noindex, robots.txt, erreur serveur, etc.
Deuxième vérification : testez l'accessibilité directe avec curl -I https://votresite.com ou un outil comme Screaming Frog. Vérifiez le statut HTTP, les en-têtes (X-Robots-Tag), et la présence éventuelle d'une balise meta robots dans le <head>.
Troisième point : consultez votre fichier robots.txt via votresite.com/robots.txt et testez-le dans Search Console (outil de test du robots.txt). Une seule ligne mal placée suffit à tout bloquer.
Que faire si la page est vide aux yeux de Googlebot ?
Comparez le HTML source (Ctrl+U dans le navigateur) et le DOM affiché après exécution JavaScript. Si le contenu principal n'apparaît que dans le DOM final, c'est un problème de rendu côté client.
Solutions possibles : passer en rendu côté serveur (SSR), utiliser la pré-génération statique (SSG), ou au minimum ajouter du contenu HTML de base directement dans la réponse serveur.
Attention : Google peut finir par indexer le contenu JavaScript via le second rendu — mais ça prend du temps, et ce n'est jamais garanti. Mieux vaut ne pas miser là-dessus pour une homepage.
Quelles erreurs éviter pour assurer une indexation fluide ?
Ne laissez jamais une balise noindex active en production. Mettez en place des alertes automatiques (via monitoring ou CI/CD) pour détecter cette balise sur les pages stratégiques.
Ne bloquez pas l'accès aux ressources critiques (CSS, JS) dans le robots.txt — même si Google peut techniquement indexer la page, cela perturbe le rendu et la compréhension du contenu.
Évitez les redirections multiples vers la homepage. Une chaîne 301 → 302 → 200 ralentit le crawl et peut créer des ambiguïtés d'indexation.
- Vérifier le statut HTTP de la homepage (doit être 200, pas 3xx ou 5xx)
- Inspecter le fichier robots.txt et tester avec l'outil Search Console
- Contrôler l'absence de balise noindex dans le
<head>et les en-têtes HTTP - S'assurer que le contenu textuel est présent dans le HTML source, pas uniquement en JavaScript
- Vérifier qu'au moins un lien externe ou un sitemap XML pointe vers la homepage
- Consulter Search Console pour toute action manuelle ou demande de suppression active
- Comparer logs serveur et rapports de crawl pour identifier d'éventuelles erreurs intermittentes
Les six causes listées par Mueller sont claires, mais leur diagnostic croisé demande rigueur et méthode. Une homepage qui refuse de s'indexer cache souvent plusieurs problèmes superposés — un robots.txt défaillant et une balise noindex oubliée, par exemple.
La complexité apparente de ces vérifications, surtout sur des stacks techniques hybrides (SSR/CSR, CDN, environnements multiples), peut justifier un audit SEO technique approfondi. Les agences SEO spécialisées disposent d'outils de crawl avancés, de monitoring continu et d'une expertise terrain qui accélère le diagnostic — et surtout, qui évite de passer à côté d'un problème structurel sous-jacent.
❓ Questions frequentes
Une homepage peut-elle être crawlée mais non indexée ?
Combien de temps faut-il attendre avant de diagnostiquer un problème d'indexation ?
Un site 100% JavaScript peut-il indexer sa homepage normalement ?
Faut-il soumettre manuellement la homepage via Search Console pour accélérer l'indexation ?
Une homepage sans backlinks externes peut-elle s'indexer ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.