Declaration officielle
Ce qu'il faut comprendre
Qu'est-ce que Google considère exactement comme du scraping de contenu ?
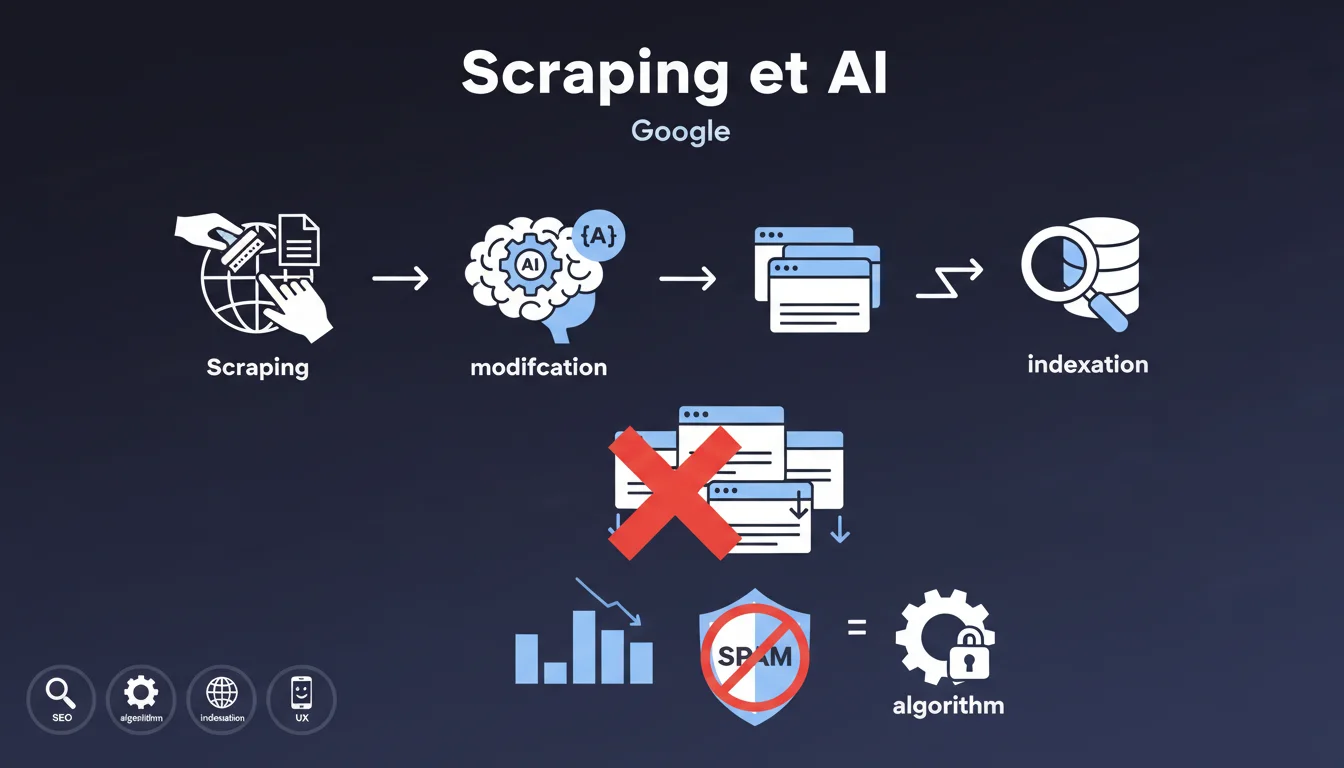
Le scraping de contenu consiste à copier des textes publiés sur d'autres sites web pour les republier sur son propre site. Google précise que même si ce contenu est modifié par des algorithmes d'intelligence artificielle, cela reste une violation de ses politiques anti-spam.
Cette position reflète la volonté de Google de pénaliser les sites qui ne créent pas de valeur originale pour les utilisateurs. La simple transformation automatisée d'un contenu existant ne suffit pas à le rendre légitime aux yeux du moteur.
Comment Google détecte-t-il ces pratiques de scraping ?
Google dispose de nombreux algorithmes spécifiquement conçus pour identifier le contenu dupliqué ou faiblement transformé. Ces systèmes analysent les similarités sémantiques et les patterns de publication suspects.
Lorsqu'un site est identifié comme pratiquant le scraping, il subit une rétrogradation dans les résultats de recherche. Cette pénalité peut affecter l'ensemble du domaine et compromettre durablement sa visibilité.
Pourquoi Google encourage-t-il les spam reports malgré leur efficacité limitée ?
Les rapports de spam constituent un signal supplémentaire pour Google, même si leur traitement n'est pas immédiat. Ils permettent d'enrichir les données d'entraînement des algorithmes de détection.
Dans la pratique, les sites spammeurs peuvent effectivement continuer leurs activités pendant plusieurs mois avant détection. Cette réalité témoigne des limites actuelles des systèmes automatisés de Google.
- Le scraping modifié par IA reste considéré comme du spam par Google
- Les algorithmes de détection existent mais ne sont pas instantanés
- Les pénalités peuvent affecter l'ensemble du domaine
- La création de contenu original reste la seule approche viable à long terme
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment la situation actuelle sur le terrain ?
En réalité, on observe quotidiennement des sites utilisant du contenu scrapé et transformé par IA qui performent encore très bien dans les SERPs. Cette contradiction entre le discours officiel et la réalité montre les limites des algorithmes actuels de Google.
L'écart entre détection et action peut s'étendre sur 6 à 12 mois, voire plus. Durant cette période, les sites spammeurs peuvent générer un trafic considérable et monétiser leur audience avant d'être pénalisés.
Quelles nuances apporter à cette position officielle de Google ?
Il existe une zone grise importante entre le scraping pur et la curation légitimement enrichie. Certains sites agrègent du contenu de sources multiples et y ajoutent une analyse substantielle, ce qui peut être acceptable.
La différence fondamentale réside dans la valeur ajoutée apportée. Si votre intervention humaine et votre expertise créent une perspective unique et utile, vous sortez de la catégorie du scraping condamnable.
Dans quels cas peut-on légitimement réutiliser du contenu existant ?
Les citations avec attribution, les extraits courts dans un contexte d'analyse, ou la syndication autorisée sont parfaitement légitimes. Le point clé est le consentement du créateur original et la proportion de contenu original vs réutilisé.
Un article qui cite 3-4 sources avec 200 mots d'extraits dans un contenu de 2000 mots originaux ne pose généralement pas de problème. Le ratio et l'intention éditoriale font toute la différence.
Impact pratique et recommandations
Comment vérifier que votre stratégie de contenu est conforme aux guidelines Google ?
Utilisez des outils comme Copyscape ou Siteliner pour analyser la similarité de votre contenu avec d'autres pages web. Un taux de duplication supérieur à 30% devrait vous alerter.
Évaluez chaque page selon le principe de valeur ajoutée substantielle. Demandez-vous honnêtement : ce contenu apporte-t-il quelque chose d'unique que l'utilisateur ne trouverait pas ailleurs ?
Quelles actions entreprendre si vous avez déjà du contenu problématique ?
Effectuez un audit complet de votre site pour identifier les pages à risque. Priorisez celles qui génèrent le plus de trafic ou qui sont stratégiquement importantes.
Pour chaque page problématique, vous avez trois options : la réécrire entièrement, l'enrichir substantiellement avec du contenu original, ou la supprimer et implémenter une redirection 301.
- Auditer l'ensemble du site avec des outils de détection de duplication
- Identifier les pages avec un taux de similarité supérieur à 30%
- Réécrire en profondeur ou supprimer les contenus à risque
- Établir un processus de création de contenu original avec des rédacteurs qualifiés
- Former vos équipes aux bonnes pratiques éditoriales
- Mettre en place une revue qualité systématique avant publication
- Documenter vos sources et citations de manière transparente
- Monitorer régulièrement votre positionnement pour détecter d'éventuelles pénalités
Quelle stratégie de contenu adopter pour le long terme ?
Investissez dans une ligne éditoriale forte basée sur votre expertise métier. Le contenu original prend plus de temps à produire mais génère des résultats durables et sans risque de pénalité.
Privilégiez la qualité à la quantité. Un article de 2000 mots vraiment utile et unique surperformera toujours 10 articles médiocres scrapés et transformés.
💬 Commentaires (0)
Soyez le premier à commenter.