Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ L'attribut HTML loading=lazy suffit-il vraiment pour éviter les problèmes d'indexation ?
- □ Faut-il vraiment bannir le lazy loading des images hero ?
- □ Le lazy loading tue-t-il vraiment votre LCP ?
- □ Comment vérifier que votre lazy loading n'empêche pas Google de voir vos images ?
- □ Le lazy loading natif de WordPress améliore-t-il vraiment votre SEO ?
- □ Le lazy loading améliore-t-il vraiment votre SEO ou seulement vos performances ?
- □ Votre LCP est un bloc de texte chargé en JavaScript : comment Google le mesure-t-il vraiment ?
- □ Le lazy loading natif HTML suffit-il vraiment pour optimiser le crawl de vos pages ?
- □ Le lazy loading sabote-t-il l'indexation de vos images dans Google ?
- □ Les images en CSS sont-elles vraiment invisibles pour le référencement Google ?
- □ Infinite scroll et lazy loading : pourquoi Google insiste-t-il sur leur différence fondamentale ?
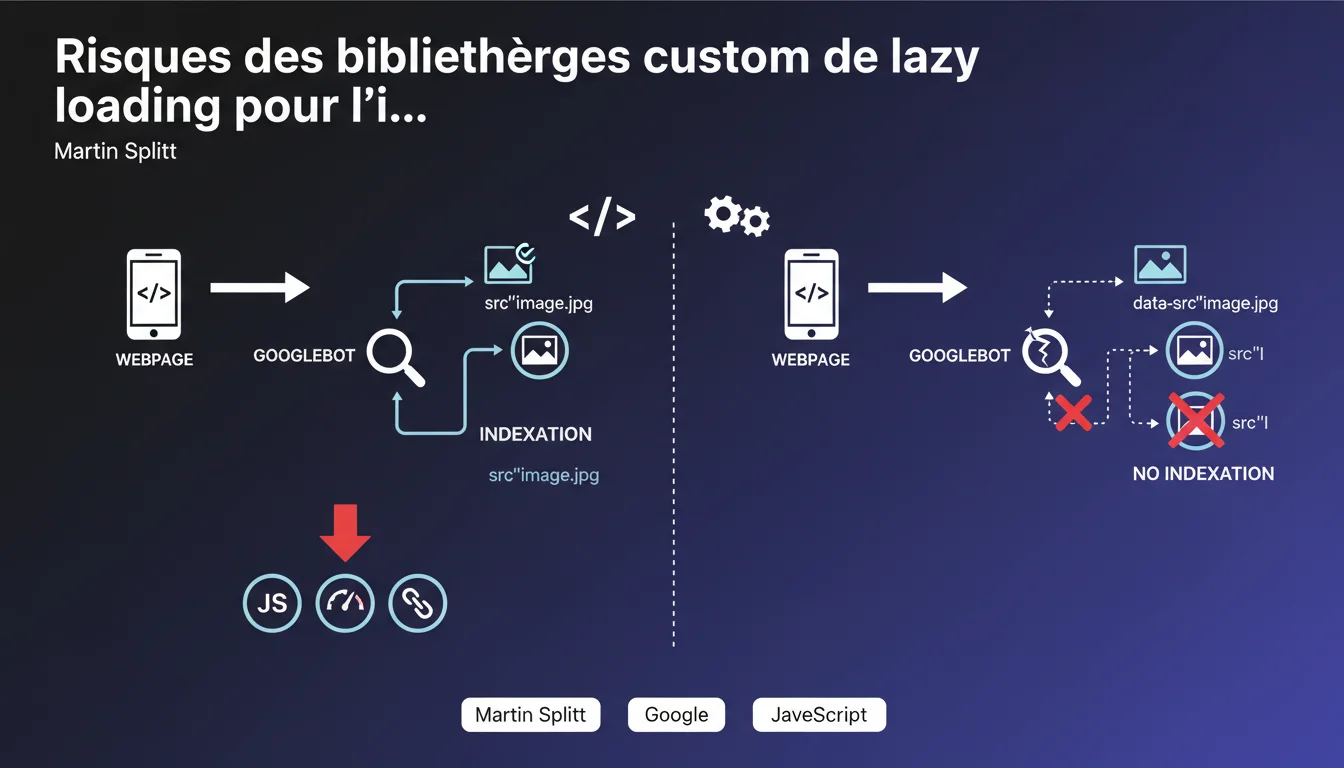
Les bibliothèques de lazy loading custom qui utilisent 'data-src' au lieu de 'src' empêchent Googlebot d'indexer vos images. Sans attribut 'src' correctement renseigné, l'image reste invisible pour Google. Martin Splitt rappelle une règle fondamentale : si le HTML ne contient pas un 'src' exploitable, l'image n'existe pas pour le moteur.
Ce qu'il faut comprendre
Pourquoi l'attribut 'src' est-il si critique pour l'indexation des images ?
Googlebot analyse le HTML brut avant toute exécution JavaScript. Si votre bibliothèque custom stocke l'URL de l'image dans un attribut comme 'data-src', le bot ne voit qu'une balise vide au moment du premier crawl.
Contrairement aux bibliothèques modernes qui hydratent progressivement le DOM, certaines solutions artisanales ne renseignent le src réel qu'après interaction utilisateur ou événement JavaScript. Résultat : l'image n'apparaît jamais dans Google Images et ne contribue pas au SEO visuel de la page.
Les bibliothèques natives évitent-elles ce problème ?
Oui, largement. L'attribut loading="lazy" du HTML5 est désormais reconnu et géré par tous les navigateurs modernes — et par Googlebot. Il diffère le chargement tout en gardant l'attribut 'src' exploitable dès le rendu initial.
Les frameworks comme Next.js ou Nuxt ont intégré ce mécanisme nativement. Ils génèrent un 'src' valide même si l'image n'est pas encore chargée côté client, ce qui préserve la visibilité pour les moteurs.
Que se passe-t-il si le JavaScript finit par s'exécuter côté Google ?
Google peut exécuter du JavaScript, mais avec des limites : budget crawl, timeout, ressources limitées. Si votre script custom tarde à s'initialiser ou dépend d'interactions utilisateur, l'image restera invisible lors du second passage.
Compter sur l'exécution JS pour révéler vos images revient à jouer à la roulette russe avec votre indexation. Surtout quand des solutions natives existent et fonctionnent sans friction.
- Googlebot lit le HTML initial, pas les promesses JavaScript
- Un 'data-src' sans 'src' rend l'image invisible au crawl
- L'attribut loading="lazy" HTML5 combine performance et SEO sans compromis
- Les bibliothèques custom nécessitent un fallback 'src' pour garantir l'indexation
- Tester avec l'outil Inspection d'URL de la Search Console révèle ce que Google voit réellement
Avis d'un expert SEO
Cette déclaration contredit-elle les observations terrain sur le rendu JavaScript ?
Pas vraiment. On sait que Google exécute du JS, mais Martin Splitt rappelle une réalité technique souvent oubliée : le crawl initial reste déterminant. Si l'attribut 'src' manque au premier passage, l'image peut ne jamais être découverte, même si le JS finit par s'exécuter.
Les tests avec des bibliothèques comme LazyLoad ou Lozad montrent que sans un noscript fallback ou un 'src' pré-rempli, le taux d'indexation des images chute drastiquement. Ce n'est pas une question de capacité technique de Google — c'est une question de priorisation et de budget crawl.
Pourquoi certains sites custom s'en sortent quand même ?
Deux raisons principales. Première hypothèse : ils ont un budget crawl généreux et Google revisite suffisamment souvent pour capturer le rendu post-JS. Mais c'est un pari risqué — rien ne garantit que ce budget restera stable.
Deuxième piste : leur implémentation inclut un 'src' par défaut, même si c'est un placeholder 1x1px ou une version basse résolution. Cela suffit à déclencher la détection, même si l'image finale charge plus tard. Soyons honnêtes — la plupart des devs custom ne pensent pas à ce détail.
Quelles bibliothèques custom posent le plus problème ?
Les solutions maison écrites avant 2018, quand le lazy loading natif n'existait pas encore. Beaucoup utilisent des observers custom ou des librairies obsolètes comme Unveil.js sans maintenance depuis des années.
Et c'est là que ça coince : ces scripts attendent souvent un événement scroll ou un seuil de viewport avant de peupler le 'src'. Pour un bot qui parse le HTML statique, ces images n'existent tout simplement pas.
Impact pratique et recommandations
Comment vérifier si mes images sont correctement indexables ?
Première étape : ouvrez votre navigateur en mode navigation privée, désactivez JavaScript complètement (dans les DevTools > Settings > Debugger), et rechargez la page. Si vos images ne s'affichent pas, Googlebot ne les voit pas non plus.
Deuxième vérification : utilisez l'outil Inspection d'URL dans la Search Console. Consultez l'onglet "HTML rendu" et cherchez vos balises . Si le 'src' est vide ou contient un placeholder générique, vous avez un souci.
Troisième contrôle : lancez un crawl avec Screaming Frog en mode JavaScript désactivé. Comparez le nombre d'images détectées avec un crawl JS activé. Un écart significatif confirme le problème.
Que faut-il modifier concrètement dans le code ?
Solution immédiate : passez à l'attribut loading="lazy" natif. Remplacez vos par des
. C'est supporté par tous les navigateurs modernes depuis 2020 et fonctionne nativement avec Googlebot.
Si vous devez absolument garder une bibliothèque custom — par exemple pour des besoins de fallback sur des navigateurs legacy — assurez-vous que le 'src' initial contient une URL valide, même si c'est une version basse résolution ou un placeholder SVG. Votre JS peut ensuite remplacer ce 'src' par la version HD une fois le viewport atteint.
Alternative élégante : utilisez une balise contenant une version complète de l'image avec 'src' renseigné. Google crawle le contenu noscript et indexera cette version de secours.
Quelles erreurs techniques faut-il absolument éviter ?
Ne comptez jamais sur le JavaScript pour révéler l'existence d'une ressource critique. Le JS doit améliorer l'expérience, pas conditionner la visibilité SEO de vos contenus.
Évitez les bibliothèques qui nécessitent une initialisation manuelle ou qui dépendent d'événements utilisateur pour peupler le DOM. Google ne scrolle pas, ne clique pas, n'attend pas 5 secondes que votre bundle JS se charge.
Et surtout — testez systématiquement après chaque modification. Un déploiement mal configuré peut casser l'indexation de centaines d'images en une seule mise en production.
- Auditer toutes les pages avec images pour vérifier la présence de l'attribut 'src' dans le HTML brut
- Migrer vers loading="lazy" natif ou implémenter un fallback 'src' valide
- Tester avec JavaScript désactivé pour simuler le crawl initial de Googlebot
- Utiliser l'Inspection d'URL Search Console sur des pages stratégiques avec images
- Comparer le nombre d'images indexées avant/après modification via Google Images
- Mettre en place un monitoring continu avec Screaming Frog ou équivalent
- Documenter les modifications pour éviter les régressions lors des prochains déploiements
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/08/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.