Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Le HTML sémantique est-il vraiment déterminant pour le référencement naturel ?
- □ Le HTML sémantique est-il vraiment inutile pour le référencement ?
- □ Faut-il vraiment utiliser des balises Hn plutôt que styler visuellement ses titres ?
- □ Faut-il vraiment placer les images près du texte pour améliorer leur référencement ?
- □ Faut-il vraiment bannir les tableaux HTML pour la mise en page ?
- □ Faut-il privilégier les balises sémantiques <section> et <article> plutôt que les <div> pour le SEO ?
- □ Le HTML sémantique améliore-t-il vraiment votre référencement ?
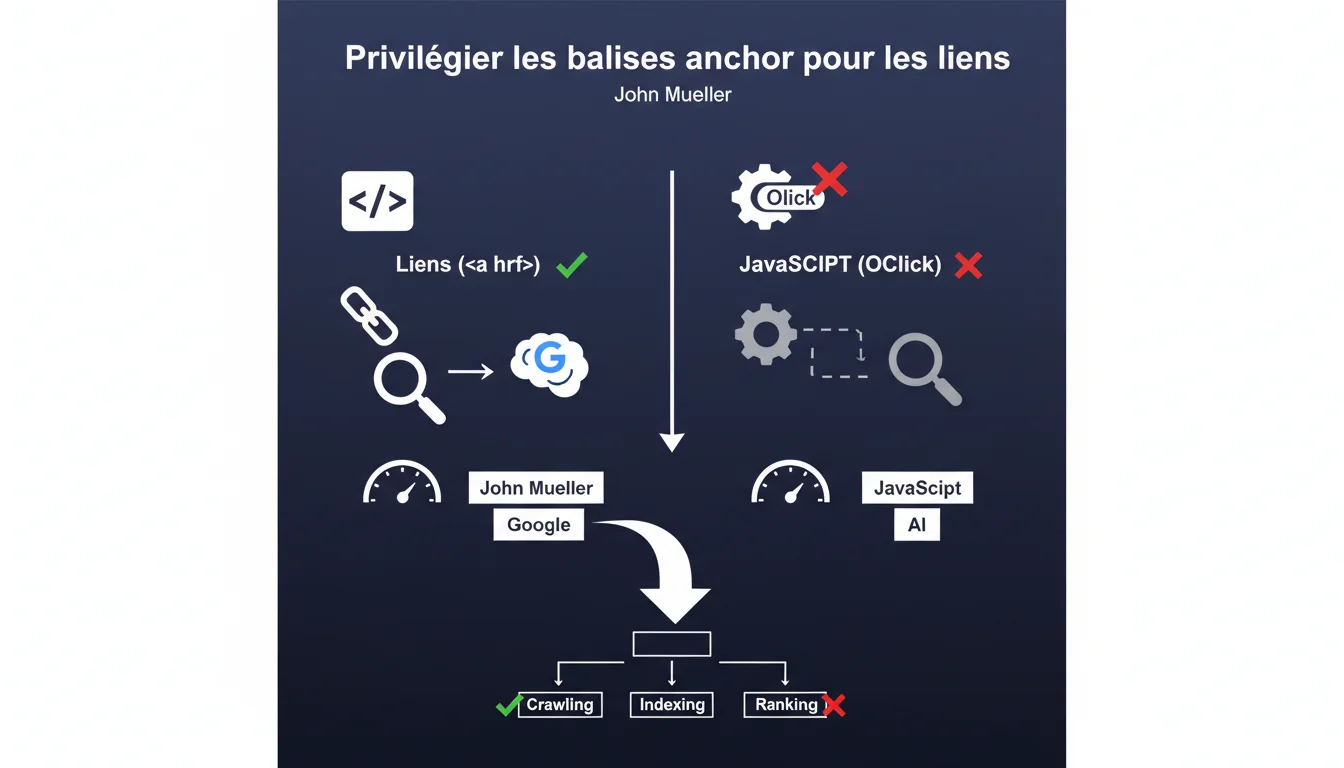
Google recommande d'utiliser des balises <a> classiques plutôt que des gestionnaires onclick JavaScript pour créer des liens. L'enjeu : permettre au moteur d'identifier et de suivre correctement les URLs. En pratique, cette directive révèle les limites persistantes du crawl JavaScript, même si Google affirme le contraire depuis des années.
Ce qu'il faut comprendre
Pourquoi Google fait-il encore cette recommandation en pleine ère JavaScript ?
Parce que Google crawle en deux temps : un premier passage HTML pur, puis un second rendu JavaScript différé. Les liens créés via onclick sans balise avec href valide ne sont détectés qu'au second passage — quand ils le sont.
Concrètement ? Un lien comme <div onclick="location.href='/page'"> n'a aucune garantie d'être crawlé. Google doit exécuter le JavaScript, interpréter le gestionnaire d'événement, et deviner l'intention de navigation. Rien n'est explicite.
Qu'est-ce qui différencie techniquement une balise d'un onclick ?
La balise <a href="/page"> expose l'URL directement dans le DOM HTML initial. Google la voit immédiatement, sans exécution de code. L'attribut href est un signal clair et universel : « ceci est un lien vers cette destination ».
Un onclick nécessite l'exécution JavaScript complète. Google doit charger les scripts, les exécuter dans son moteur de rendu, puis analyser les événements déclenchés. C'est coûteux en ressources et sujet aux échecs silencieux : timeout, script bloqué, erreur d'exécution.
Est-ce que cette directive impacte tous les types de sites ?
Les sites statiques ou classiques ne sont pas concernés — ils utilisent déjà des balises . Les applications JavaScript (SPA React, Vue, Angular) sont directement visées, surtout celles qui gèrent la navigation via du code custom.
Les frameworks modernes génèrent généralement des <a href> corrects (Next.js Link, Nuxt NuxtLink, Gatsby Link). Le problème surgit avec les implémentations maison ou les composants UI qui simulent des liens sans en être.
- Signal explicite : une balise avec href valide est immédiatement détectable par Googlebot
- Crawl en deux temps : les liens JavaScript purs ne sont détectés qu'après rendu complet
- Coût de crawl : le rendu JavaScript consomme du crawl budget et augmente les risques d'échec
- Progressive enhancement : un lien fonctionne même si JavaScript échoue ou est désactivé
- Accessibilité bonus : les lecteurs d'écran et la navigation clavier dépendent des balises sémantiques
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec ce que Google affirme ailleurs ?
Non — et c'est là que ça coince. Depuis 2015, Google répète que son moteur « comprend JavaScript comme un navigateur moderne ». En 2019, ils ont annoncé utiliser une version evergreen de Chromium. Pourquoi alors cette insistance sur les balises si le crawl JavaScript est si performant ?
Parce que la réalité terrain contredit le discours marketing. Les tests montrent régulièrement des liens JavaScript non découverts, des contenus non indexés, des timeouts de rendu. Le rendering est coûteux, lent, et Google le priorise. Tous les liens JavaScript ne passent pas la barre. [À vérifier] sur des sites à fort volume de pages.
Dans quels cas précis un lien JavaScript pose-t-il problème ?
Premier cas : les liens chargés après interaction. Un menu déroulant qui génère des <div onclick> au survol ne sera jamais crawlé — Googlebot ne simule pas les interactions utilisateur complexes. Les liens doivent être dans le DOM initial ou chargés automatiquement.
Deuxième cas : les gestionnaires événementiels complexes. Un onclick qui déclenche une fonction qui appelle une autre fonction qui modifie window.location... Google peut abandonner en cours de route. Plus la chaîne d'exécution est longue, plus le risque d'échec augmente.
Troisième cas : les liens conditionnels côté client. Du code qui affiche un lien seulement si une variable localStorage existe, ou si une API répond — Google n'a pas ce contexte. Il voit la version « déconnecté » ou « par défaut ».
event.preventDefault() puis navigue manuellement reste risqué. Google suit le href, mais certains frameworks annulent le comportement par défaut. Testez avec l'outil d'inspection d'URL Search Console.Y a-t-il des situations où onclick est acceptable ?
Oui, pour des actions non-navigationnelles : ouvrir une modale, afficher un menu, déclencher une animation. Tout ce qui n'est pas censé mener à une nouvelle URL crawlable. Si c'est un lien SEO — destination indexable — alors balise obligatoire.
Cas limite : un <a href="/page" onclick="track()"> où onclick fait du tracking puis laisse le navigateur suivre le href. C'est acceptable — le href reste présent et fonctionnel. Le JavaScript est une couche additionnelle, pas le mécanisme principal.
Impact pratique et recommandations
Comment auditer les liens de mon site pour détecter les problèmes ?
Utilisez Screaming Frog en mode JavaScript : comparez les liens découverts en crawl HTML pur vs rendu JavaScript. Si des URLs n'apparaissent qu'en mode JS, elles dépendent du rendu — risque identifié.
Testez avec Search Console : prenez 10 URLs clés avec navigation JavaScript, passez-les dans l'outil d'inspection d'URL, vérifiez l'onglet « Autres informations » > « Liens sortants détectés ». Si vos menus ou paginations n'apparaissent pas, Google ne les voit pas.
Quelles modifications concrètes apporter au code ?
Remplacez systématiquement <div onclick="navigate()"> par <a href="/page">. Si vous devez garder du JavaScript pour enrichir le comportement (tracking, animation), ajoutez-le en couche supplémentaire sur une vraie balise .
Pour les SPAs : vérifiez que vos composants de navigation (Link, RouterLink, etc.) génèrent bien des <a href> dans le HTML final. Inspectez le DOM rendu, pas juste le code source — certains frameworks conditionnent l'affichage du href.
Si votre navigation repose sur history.pushState() sans href correspondant, ajoutez des liens fallback : un <a href="/page"> visible qui déclenche le JavaScript moderne, mais reste fonctionnel si JS échoue.
Comment valider que les corrections fonctionnent ?
- Crawler le site avec Screaming Frog en mode HTML uniquement : tous les liens critiques doivent être détectés
- Vérifier que chaque lien de navigation, menu, pagination utilise
<a href="URL"> - Tester 5-10 URLs dans Search Console outil d'inspection, onglet liens sortants : confirmation de découverte
- Désactiver JavaScript dans Chrome DevTools, naviguer sur le site : les liens doivent rester cliquables
- Auditer les événements onclick/addEventListener : aucun ne doit être le seul mécanisme de navigation vers une page indexable
- Valider avec Lighthouse ou PageSpeed Insights : aucun avertissement sur liens non-crawlables
❓ Questions frequentes
Est-ce que les frameworks JavaScript modernes comme React ou Vue génèrent automatiquement des balises <a> correctes ?
Un lien avec href="#" et onclick qui navigue via JavaScript est-il acceptable pour Google ?
Les liens générés dynamiquement après le chargement de la page sont-ils crawlés par Google ?
Peut-on utiliser onclick pour du tracking tout en gardant un href valide ?
Comment tester si mes liens JavaScript sont bien découverts par Google ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.