Declaration officielle
Ce qu'il faut comprendre
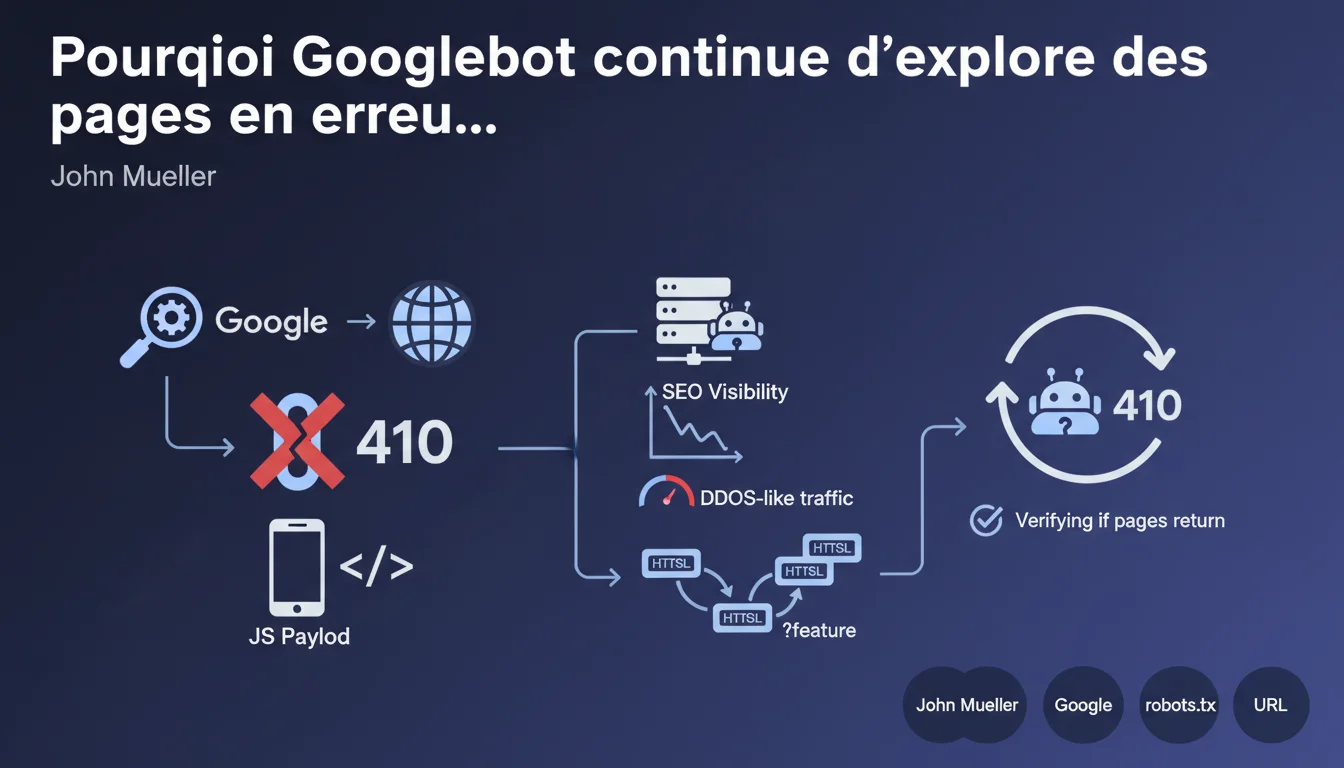
Cette déclaration révèle un comportement méconnu de Googlebot : les pages renvoyant un code HTTP 410 (Gone) ne sont pas définitivement ignorées par le crawler. Contrairement à l'idée reçue selon laquelle un 410 signale à Google qu'une page est supprimée à jamais, le bot continue à vérifier périodiquement ces URLs pour s'assurer qu'elles ne reviennent pas.
Le cas décrit illustre une situation extrême : 2,4 millions de requêtes sur une seule URL, provoquant un volume de crawl proche d'une attaque DDoS. L'origine du problème était une exposition accidentelle d'URLs paramétrées via un payload JSON généré automatiquement par Next.js. Ces URLs, bien qu'inaccessibles et marquées 410, ont été découvertes et indexées par Google, qui a ensuite tenté de les re-crawler massivement.
La réaction instinctive - bloquer via robots.txt - comporte des risques majeurs. Un mauvais paramétrage du robots.txt peut empêcher le rendu correct des pages importantes, particulièrement dans les architectures JavaScript modernes où certaines ressources sont critiques pour l'affichage.
- Le code 410 n'empêche pas définitivement le crawl, contrairement aux attentes
- L'exposition accidentelle d'URLs (JSON, sitemaps, liens internes) peut déclencher un crawl massif
- Le budget crawl peut être dilapidé sur des pages inutiles même en 410
- Bloquer via robots.txt nécessite une analyse approfondie des dépendances
- La corrélation entre crawl excessif et perte de visibilité n'est pas automatique
Avis d'un expert SEO
Cette analyse de Mueller est cohérente avec ce que j'observe depuis des années : Google maintient une vérification périodique même sur les contenus marqués comme définitivement supprimés. C'est logique d'un point de vue algorithmique - les sites peuvent se tromper, faire des erreurs de configuration, ou réactiver du contenu. Le moteur préfère vérifier plutôt que de perdre définitivement la trace de contenus potentiellement pertinents.
Cependant, il faut nuancer le propos de Mueller sur un point crucial : il invite à ne pas s'arrêter à une explication superficielle. C'est fondamental. Dans 90% des cas que j'ai analysés où un éditeur attribue une chute de trafic au comportement de Googlebot, la vraie cause est ailleurs : perte de liens, cannibalisation de contenu, mise à jour algorithmique, problèmes de qualité. Le crawl excessif est souvent un symptôme, pas la maladie.
Impact pratique et recommandations
- Auditez l'origine de l'exposition : Recherchez dans vos payloads JSON, fichiers JavaScript buildés, sitemaps XML/HTML, et liens internes les références à ces URLs problématiques
- Nettoyez les sources d'exposition : Configurez Next.js/Nuxt pour exclure ces patterns des builds, supprimez les URLs des sitemaps, éliminez les liens internes orphelins
- Ne bloquez PAS immédiatement via robots.txt : Testez d'abord l'impact sur le rendu avec l'outil d'inspection d'URL de Search Console pour chaque pattern que vous envisagez de bloquer
- Utilisez le paramètre crawl-delay : Dans Search Console, ajustez la vitesse de crawl si le volume pose un problème d'infrastructure réel (disponibilité sporadique selon les comptes)
- Analysez la vraie cause de la perte de trafic : Comparez avec Google Analytics les pages ayant perdu du trafic vs celles sur-crawlées. Cherchez des corrélations temporelles avec des mises à jour algorithmiques (Core Updates, Helpful Content)
- Monitoring post-nettoyage : Après suppression des sources d'exposition, le crawl devrait diminuer naturellement sur 15-30 jours. Si ce n'est pas le cas, envisagez alors un blocage ciblé
- Pattern de URLs paramétrées : Si vos 410 proviennent de paramètres (?feature=, ?id=), configurez la gestion des paramètres dans Search Console pour indiquer à Google lesquels ignorer
- Implémentez le noindex avant le 410 : Pour les futures suppressions massives, passez d'abord par une phase noindex (quelques semaines) avant de basculer en 410, cela réduit l'intérêt de Google pour ces pages
💬 Commentaires (0)
Soyez le premier à commenter.