Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Page Experience sur desktop : faut-il vraiment s'inquiéter de ce nouveau facteur de classement ?
- □ Comment Google évalue-t-il vraiment la qualité de vos avis produits ?
- □ Faut-il vraiment migrer vers Google Analytics 4 pour ne pas perdre ses données de trafic ?
- □ Faut-il vraiment exploiter Search Console avec Data Studio pour optimiser son suivi SEO ?
- □ La balise 'indexifembedded' de Google va-t-elle changer votre stratégie d'indexation ?
- □ Search Console Insights : l'outil qui rend Search Console inutile pour les créateurs de contenu ?
- □ Pourquoi Google lance une série vidéo pour rapprocher SEO et développeurs ?
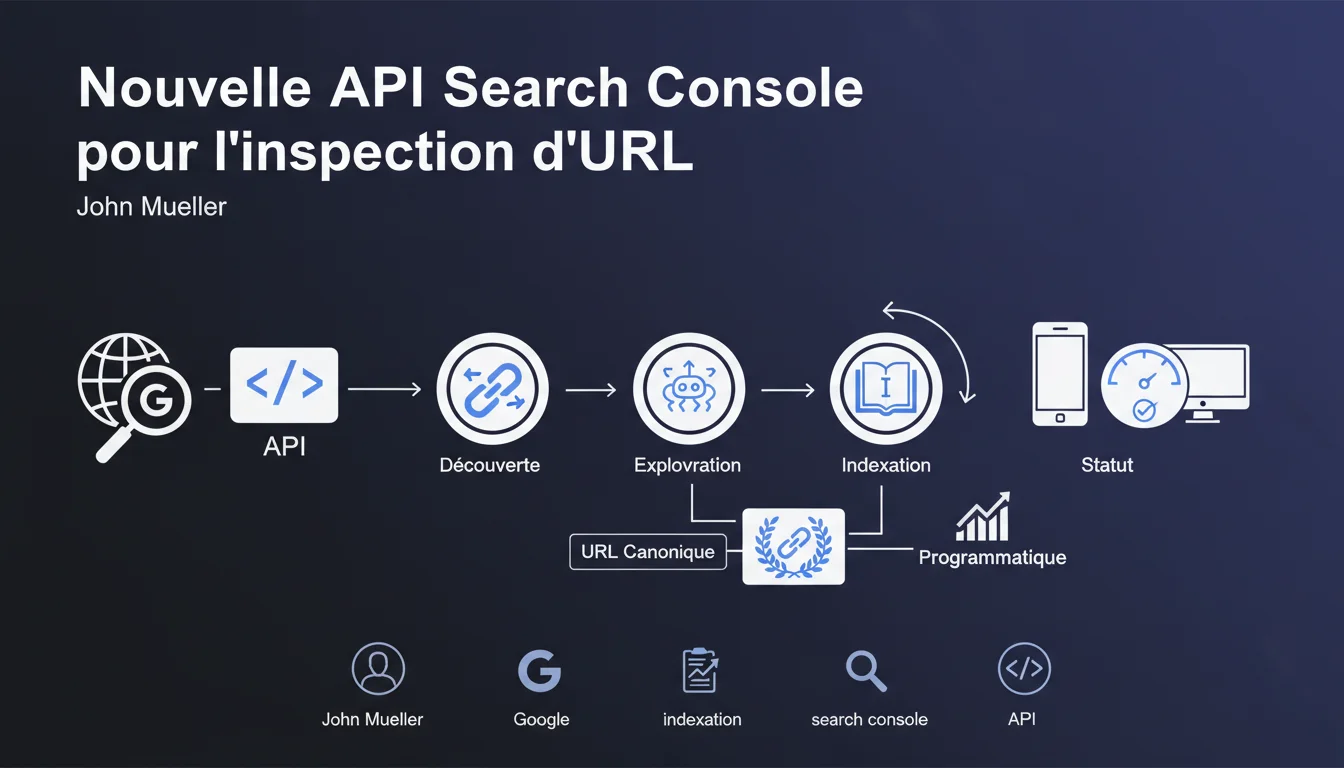
Google lance une API pour l'inspection d'URL qui permet d'automatiser la vérification du statut d'indexation. Concrètement, vous pouvez désormais checker programmatiquement si une page est découverte, explorée, indexée et quelle canonique a été retenue. Un gain de temps massif pour les sites à forte volumétrie.
Ce qu'il faut comprendre
Qu'est-ce que cette API change pour les SEO qui gèrent des sites volumineux ?
Jusqu'ici, l'inspection d'URL dans Search Console était un processus manuel — pratique pour vérifier une poignée de pages, pénible dès qu'on dépasse la dizaine. Cette API permet d'interroger Google à l'échelle : statut d'indexation, erreurs d'exploration, URL canonique sélectionnée, tout ça récupérable via des scripts.
Pour un site e-commerce avec des milliers de fiches produits, ou une plateforme média qui publie des centaines d'articles par mois, c'est un levier de monitoring automatisé qui change la donne.
Quelles données précises cette API expose-t-elle ?
L'API retourne les infos qu'on trouve déjà dans l'outil d'inspection : si la page a été découverte, si elle a été explorée, si elle est indexée, et quelle URL canonique Google a retenue. Elle indique aussi les éventuelles erreurs d'exploration ou de validation de balisage structuré.
Contrairement à l'API Search Console classique qui se base sur des données historiques agrégées, celle-ci permet de vérifier l'état actuel d'une URL spécifique — exactement comme si vous tapiez l'URL dans l'outil manuel.
Pourquoi Google sort cet outil maintenant ?
Google a toujours été frileux sur l'automatisation des checks d'indexation — probablement pour limiter la charge serveur. Mais la demande des SEO était là depuis des années, surtout pour les migrations, les audits de masse ou le suivi post-publication.
En ouvrant cette API, Google reconnaît implicitement que les workflows SEO modernes exigent de l'automatisation. C'est aussi un moyen de pousser les utilisateurs vers des pratiques de monitoring plus structurées plutôt que du check manuel aléatoire.
- L'API permet d'automatiser la vérification du statut d'indexation sur des volumes importants
- Elle expose les mêmes données que l'outil manuel : découverte, exploration, indexation, canonique
- C'est un signal que Google encourage les workflows SEO programmatiques et structurés
- Attention aux quotas d'utilisation — Google limite le nombre de requêtes pour éviter les abus
Avis d'un expert SEO
Cette API est-elle vraiment un game changer ou juste une commodité ?
Soyons honnêtes : pour un site de 50 pages, ça ne change rien. Mais pour tout ce qui dépasse les 500 URLs — et a fortiori pour les sites à plusieurs milliers de pages — c'est un gain de temps colossal. Fini le check manuel page par page, vous pouvez scripter un monitoring hebdomadaire et détecter les problèmes d'indexation avant qu'ils n'impactent le trafic.
Le vrai bénéfice, c'est le monitoring post-migration ou post-déploiement. Vous poussez un nouveau batch de pages en prod ? Un script tourne le lendemain pour vérifier que tout est bien indexé et que les canoniques sont correctes. Ça limite les mauvaises surprises.
Quelles sont les limites qu'il faut anticiper ?
Google ne donne pas un accès illimité — il y a des quotas de requêtes par jour. Pour un gros site, ça peut vite devenir un goulot d'étranglement si vous voulez checker l'ensemble du catalogue produit chaque semaine. Il faudra prioriser les URLs critiques.
Autre point : l'API retourne l'état actuel tel que vu par Google à l'instant T. Ça ne garantit pas que cette page restera indexée dans 48h, ni que Google n'a pas d'autres versions en cache. [A vérifier] : quelle est la latence réelle entre une modification on-site et la mise à jour de l'état dans l'API ? Google ne donne pas de SLA précis.
Dans quels cas cette API ne suffit-elle pas ?
Si vous cherchez à comprendre pourquoi une page n'est pas indexée, l'API vous dira « non indexée » mais ne donnera pas forcément tous les détails du refus — certains diagnostics restent plus lisibles dans l'interface manuelle. De même, pour les problèmes de crawl budget ou de priorisation d'exploration, l'API ne remplace pas une analyse fine des logs serveur.
Enfin, ça reste une vision Google-centrée. Si vous voulez croiser avec des données Bing ou d'autres moteurs, il faudra jongler entre plusieurs outils.
Impact pratique et recommandations
Comment intégrer cette API dans vos workflows SEO existants ?
Première étape : identifier les cas d'usage prioritaires. Migration en cours ? Post-publication de contenu critique ? Monitoring hebdomadaire des pages stratégiques ? Définissez où l'automatisation apporte le plus de valeur avant de scripter à tout-va.
Ensuite, mettez en place un script qui interroge l'API sur vos URLs cibles et stocke les résultats dans un tableau de bord — Google Sheets, Data Studio, ou un outil de BI interne. L'idée est de tracer l'évolution dans le temps : une page qui passe de « indexée » à « découverte mais non indexée » doit déclencher une alerte.
Quelles erreurs faut-il éviter en utilisant cette API ?
Ne bombardez pas l'API avec des milliers de requêtes quotidiennes sans réfléchir aux quotas. Google limite le nombre d'appels — dépassez-les et vous serez bloqué temporairement. Priorisez les URLs à forte valeur business ou celles qui ont un historique de problèmes d'indexation.
Autre piège classique : se fier uniquement à l'API sans vérifier les logs serveur. Si Google dit « non explorée », c'est bien, mais encore faut-il savoir si Googlebot a tenté de crawler et s'est pris un 500, ou s'il n'a jamais essayé. L'API donne l'état, pas toujours la cause profonde.
Que faut-il faire concrètement dès maintenant ?
Si vous gérez un site de taille significative, commencez par tester l'API sur un échantillon de pages — par exemple vos 100 URLs les plus stratégiques. Créez un script simple qui récupère le statut d'indexation et la canonique sélectionnée, puis comparez avec ce que vous observez dans Search Console manuel.
Documentez les cas où l'API retourne des infos inattendues ou contradictoires avec vos logs. Ça vous donnera une idée de la fiabilité et de la latence des données. Une fois que vous maîtrisez le comportement de l'API, élargissez progressivement le périmètre de monitoring.
- Identifiez vos cas d'usage prioritaires : migration, post-publication, monitoring récurrent
- Testez l'API sur un échantillon restreint avant de passer à l'échelle
- Mettez en place un tableau de bord automatisé pour suivre l'évolution du statut d'indexation
- Croisez les données de l'API avec vos logs serveur pour identifier les causes racines
- Respectez les quotas de requêtes et priorisez les URLs stratégiques
- Documentez les cas d'incohérence entre l'API et vos observations terrain
❓ Questions frequentes
Cette API remplace-t-elle l'outil d'inspection manuelle dans Search Console ?
Y a-t-il des limites de quota sur le nombre de requêtes par jour ?
L'API donne-t-elle des infos en temps réel ou avec un délai ?
Peut-on utiliser cette API pour forcer une réindexation ?
Quels langages de programmation sont supportés pour utiliser cette API ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 31/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.