Declaration officielle
Ce qu'il faut comprendre
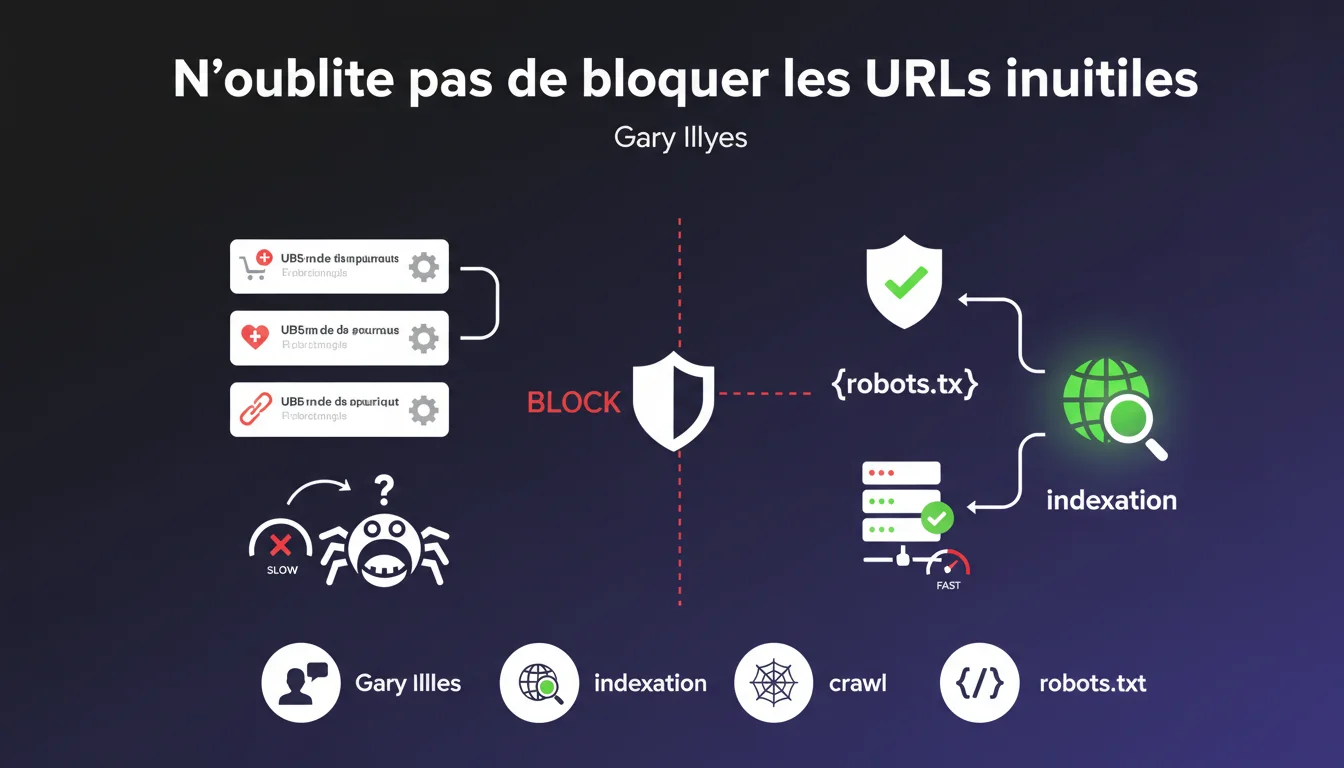
Les URLs d'action sont des pages déclenchant des fonctionnalités spécifiques sur un site web : ajout au panier, ajout aux favoris, fonctions de tri, de filtrage ou de partage. Ces pages ne contiennent généralement aucun contenu unique et n'apportent aucune valeur pour le référencement naturel.
Lorsque les robots d'indexation explorent ces URLs, ils consomment inutilement le budget de crawl du site. Ce budget représente le nombre de pages que Googlebot accepte d'explorer lors d'une session. Plus ce budget est gaspillé sur des pages sans valeur, moins les pages réellement importantes sont crawlées régulièrement.
La recommandation de Google vise à optimiser l'efficacité de l'exploration en dirigeant les robots vers les contenus stratégiques uniquement. Cela améliore également les performances du serveur en réduisant les requêtes inutiles.
- Les URLs d'action ne doivent pas être indexées ni explorées
- Le fichier robots.txt permet de bloquer ces URLs efficacement
- Cette pratique préserve le budget de crawl pour les pages importantes
- Elle réduit la charge serveur et améliore les temps de réponse
- Les sites e-commerce sont particulièrement concernés par cette problématique
Avis d'un expert SEO
Ce rappel de Google s'inscrit dans les bonnes pratiques SEO fondamentales, mais mérite quelques nuances importantes. Si bloquer les URLs d'action via robots.txt est effectivement pertinent, cette approche doit être combinée avec d'autres méthodes pour une efficacité maximale.
En pratique, il est recommandé d'utiliser également des attributs nofollow sur les liens déclenchant ces actions, ainsi que des paramètres URL dans Google Search Console pour indiquer comment traiter certains paramètres. Le robots.txt seul ne suffit pas toujours, notamment si ces URLs sont déjà indexées ou liées depuis des sites externes.
Par ailleurs, tous les sites ne sont pas également concernés. Les petits sites avec peu de pages n'ont généralement pas de problème de budget de crawl. Cette optimisation devient critique pour les sites de grande envergure avec des milliers de pages, particulièrement les plateformes e-commerce et les sites génératifs de contenu.
Impact pratique et recommandations
- Auditez votre site pour identifier toutes les URLs d'action (panier, wishlist, tri, filtres, partage social)
- Listez les paramètres URL générés dynamiquement par votre CMS ou plateforme e-commerce
- Ajoutez des directives Disallow dans votre robots.txt pour bloquer ces patterns d'URLs
- Appliquez l'attribut rel="nofollow" sur tous les liens déclenchant ces actions
- Configurez les paramètres URL dans Google Search Console pour indiquer leur traitement
- Vérifiez dans vos logs serveur que Googlebot n'explore plus ces URLs inutiles
- Pour les URLs d'action déjà indexées, ajoutez d'abord une balise noindex avant de les bloquer
- Surveillez l'évolution de votre budget de crawl via Search Console après implémentation
- Documentez les règles appliquées pour faciliter la maintenance future du robots.txt
💬 Commentaires (0)
Soyez le premier à commenter.