Declaration officielle
Autres déclarations de cette vidéo 2 ▾
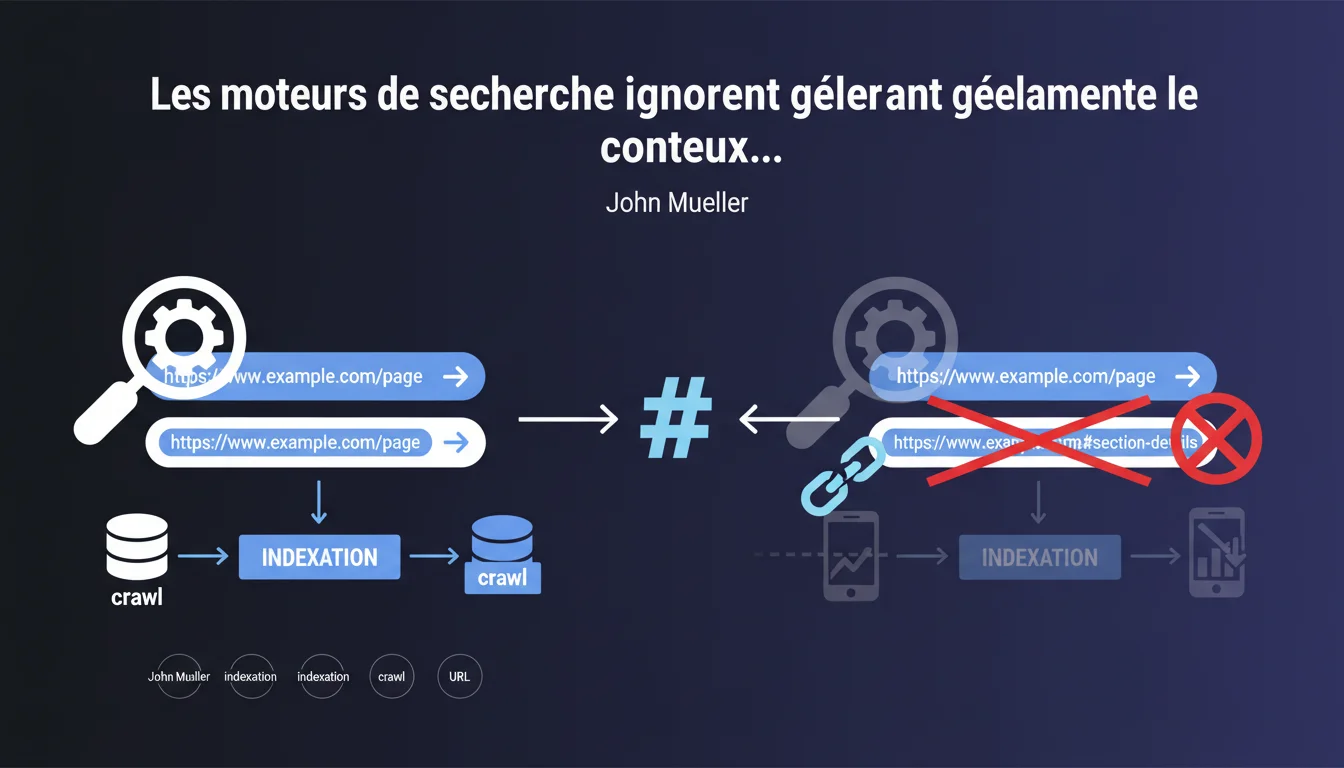
Google ignore systématiquement la partie après le # dans les URLs lors du crawl et de l'indexation. Seul le segment avant le hash compte pour le référencement. Cette règle impacte directement l'architecture des sites en JavaScript et les SPAs.
Ce qu'il faut comprendre
Pourquoi Google ignore-t-il le contenu après le hash ?
Le symbole # (hash ou fragment identifier) a été conçu à l'origine pour pointer vers une section spécifique d'une page web, pas pour identifier une ressource unique. Historiquement, tout ce qui suit le # n'est jamais envoyé au serveur — c'est traité côté client par le navigateur.
Google respecte cette convention HTTP. Quand Googlebot crawle exemple.com/page#section1 et exemple.com/page#section2, il considère qu'il s'agit de la même URL : exemple.com/page. Le fragment est purement décoratif pour le moteur.
Cette règle s'applique-t-elle sans exception ?
Mueller dit "la plupart du temps", ce qui laisse une marge d'interprétation. En pratique, Google a introduit des exceptions temporaires par le passé — notamment le schéma #! (hashbang) pour gérer les applications JavaScript avant que le rendering côté client ne soit généralisé.
Mais cette méthode est obsolète depuis des années. Aujourd'hui, avec le dynamic rendering et l'amélioration du crawl JavaScript, Google n'a plus besoin de ces artifices. Le hash est redevenu ce qu'il devrait être : un marqueur invisible pour le SEO.
Quels types de sites sont concernés ?
Les Single Page Applications (SPAs) utilisant des frameworks comme React, Vue ou Angular sont les premières impactées. Beaucoup de ces architectures utilisent des URLs avec hash pour simuler une navigation multi-pages sans rechargement.
Si votre site affiche monsite.com/#produits ou monsite.com/#contact, Google n'indexera qu'une seule page : monsite.com/. Tout le contenu "routé" après le # est invisible.
- Les URLs avec hash ne créent pas de pages distinctes aux yeux de Google
- Le contenu dynamique chargé via hash routing n'est pas indexable séparément
- Les ancres internes (#section) ne posent aucun problème — elles ne sont pas censées être crawlées
- Les SPAs doivent impérativement utiliser le History API (pushState) pour des URLs propres
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, c'est l'un des rares points où Google est parfaitement clair et constant depuis des années. Tous les tests montrent que le hash est systématiquement tronqué lors de l'indexation.
La nuance — et c'est là que Mueller reste flou — concerne le rendu JavaScript. Si votre SPA charge du contenu différent selon le fragment, Google voit techniquement ce contenu lors du rendering... mais il l'associe quand même à l'URL sans hash. Résultat : plusieurs "pages" distinctes côté utilisateur peuvent se retrouver fusionnées dans l'index sous une seule URL.
Quels pièges faut-il anticiper avec les SPAs ?
Le vrai problème n'est pas tant que Google ignore le hash — c'est que beaucoup de développeurs l'ignorent. J'ai vu des sites entiers construits avec hash routing, persuadés d'avoir 50 pages indexables alors qu'ils n'en avaient qu'une.
[À vérifier] : Google affirme rendre "la plupart" du JavaScript, mais la réalité est plus nuancée. Le rendering a des limites de temps, de budget crawl, et de complexité. Si votre contenu dépend d'interactions multiples après le chargement initial, rien ne garantit qu'il soit indexé — hash ou pas.
Les ancres internes posent-elles un problème ?
Non, et c'est important de le préciser. Utiliser #section-contact pour créer une ancre vers une partie de votre page est parfaitement légitime et n'impacte pas le SEO. Google ne va pas pénaliser ça.
Le problème surgit uniquement quand on utilise le hash pour simuler une architecture multi-pages au lieu de structurer proprement avec des URLs distinctes. C'est une question d'intention et d'usage.
Impact pratique et recommandations
Que faire si mon site utilise des URLs avec hash ?
Si vous avez une SPA avec hash routing (monsite.com/#/produits), la solution est de migrer vers le History API pour obtenir des URLs propres (monsite.com/produits). C'est techniquement faisable avec tous les frameworks modernes.
Cette migration nécessite de configurer correctement votre serveur pour qu'il serve toujours l'application principale, peu importe l'URL demandée. Sans ça, un refresh sur /produits renverra une 404. C'est une opération qui touche à la fois le front-end et l'infrastructure.
Comment vérifier que Google indexe bien mes pages ?
Utilisez la Google Search Console pour inspecter chaque URL que vous pensez indexable. Regardez l'onglet "Coverage" pour identifier les URLs ignorées ou consolidées.
Comparez le nombre de pages dans votre sitemap XML avec le nombre de pages effectivement indexées. Si vous avez un écart important et que votre site est en SPA, le hash routing est probablement en cause.
- Auditer l'architecture actuelle : identifier toutes les URLs utilisant des hashs
- Migrer vers le History API (pushState/replaceState) pour des URLs propres
- Configurer le serveur pour gérer le routing côté serveur (SSR ou fallback vers index.html)
- Mettre à jour le sitemap XML avec les nouvelles URLs sans hash
- Vérifier le rendering avec l'outil d'inspection d'URL de la GSC
- Monitorer les logs crawl pour confirmer que Googlebot accède aux bonnes URLs
- Implémenter des balises canoniques si nécessaire pour éviter la duplication
❓ Questions frequentes
Les ancres internes (#section) nuisent-elles au SEO ?
Le schéma hashbang (#!) est-il encore supporté par Google ?
Si Google rend ma SPA, voit-il le contenu chargé dynamiquement après le hash ?
Comment migrer d'un hash routing vers des URLs propres sans perdre de trafic ?
Les paramètres après le hash sont-ils transmis à Google Analytics ?
🎥 De la même vidéo 2
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/10/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.