Declaration officielle
Autres déclarations de cette vidéo 2 ▾
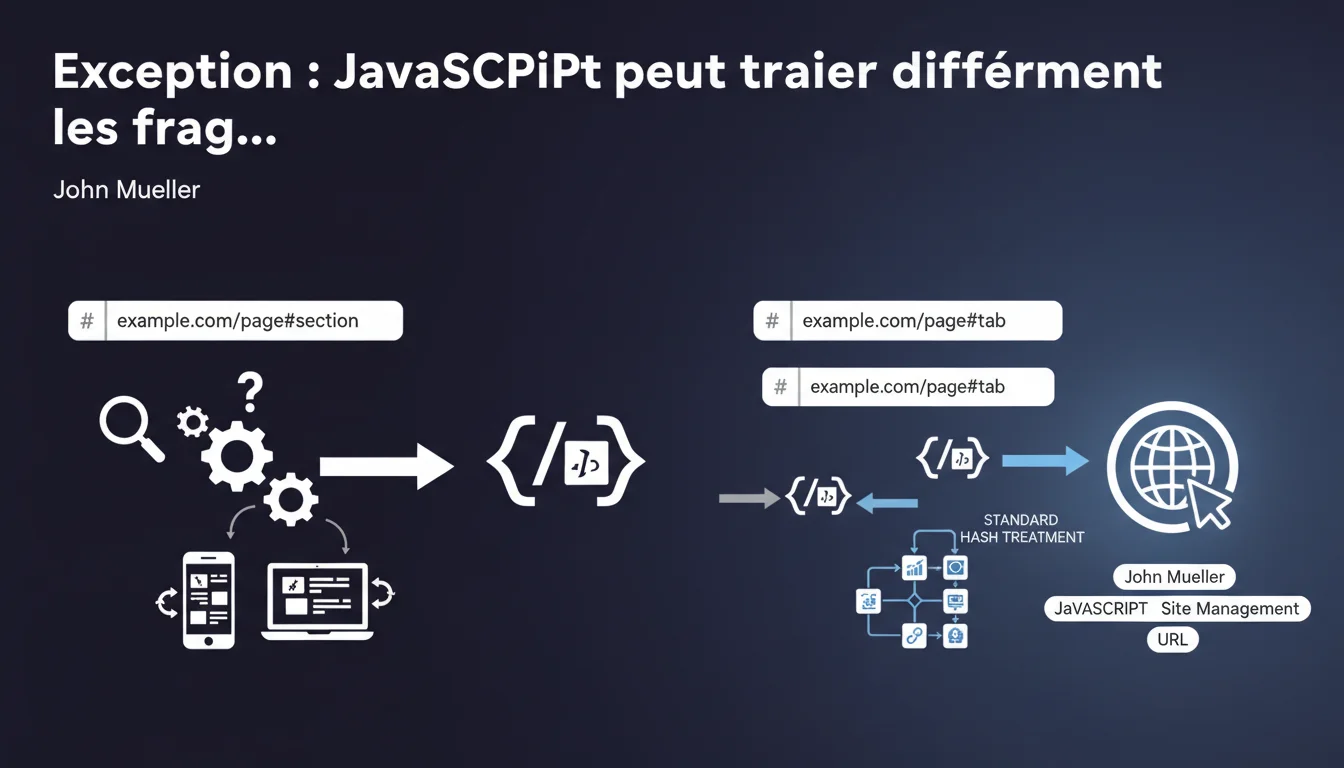
Google confirme une exception importante : quand du JavaScript manipule activement les fragments d'URL (#), le traitement par Googlebot diffère du comportement standard. Cette gestion relève alors des problématiques spécifiques aux sites JavaScript, avec des implications directes sur l'indexation et le crawl.
Ce qu'il faut comprendre
Pourquoi cette exception change-t-elle la donne pour les sites JavaScript ?
Normalement, Google ignore purement et simplement les fragments d'URL (la partie après le #). C'est une règle connue depuis des années : exemple.com/page#section1 et exemple.com/page#section2 sont considérés comme la même URL.
Mais dès qu'un script côté client utilise ces fragments pour charger du contenu dynamique ou modifier l'état de la page, on entre dans une zone grise. Le bot doit alors exécuter le JavaScript pour comprendre ce que fait réellement la page — et c'est là que ça se complique.
Qu'est-ce qui déclenche ce traitement différent concrètement ?
La différence se joue au moment du rendu. Si votre JavaScript écoute les événements hashchange ou utilise window.location.hash pour charger du contenu, Googlebot doit interpréter ce comportement.
Les Single Page Applications (SPA) sont particulièrement concernées : React Router en mode hash, les anciens frameworks Angular avec HashLocationStrategy, ou n'importe quel site qui utilise les fragments pour gérer la navigation. Dans ces cas, le traitement standard ne s'applique plus.
Quelle est la portée réelle de cette exception ?
- Sites statiques classiques : Les fragments restent ignorés, pas de changement
- SPA modernes avec routing par hash : Le JavaScript sera exécuté pour comprendre la structure
- Ancres de navigation simples : Toujours ignorées, même si vous avez du JS sur la page
- Contenu chargé dynamiquement via #fragment : Zone à risque — le rendu devient critique
- Ressources de crawl mobilisées : L'exécution JS coûte plus cher en budget de crawl
Avis d'un expert SEO
Cette déclaration est-elle alignée avec ce qu'on observe sur le terrain ?
Oui, mais Google reste délibérément flou sur les détails d'implémentation. On sait depuis des années que Googlebot exécute du JavaScript — la nouveauté ici, c'est de reconnaître officiellement que les fragments peuvent déclencher un traitement différent.
Ce qui manque ? Des exemples précis. Quand exactement le bot décide-t-il d'exécuter le JS lié aux fragments ? Tous les frameworks sont-ils traités pareil ? [À vérifier] : Google n'a jamais publié de benchmark sur la fiabilité du rendu des SPA avec hash routing versus history API.
Dans quels cas cette règle pose-t-elle problème ?
Le vrai souci, c'est le timing d'exécution. Le JavaScript Googlebot n'est pas Chrome — il y a des délais, des timeouts, des scripts qui ne se chargent pas dans le bon ordre.
Concrètement : si votre contenu principal dépend d'un fragment et que le JS met 3 secondes à s'exécuter, vous prenez un risque. J'ai vu des sites perdre 40% de leurs pages indexées après une migration vers un routing par hash mal configuré.
Faut-il totalement éviter les fragments d'URL en SEO ?
Non, ce serait excessif. Les ancres classiques (#section-contact) fonctionnent très bien et ne posent aucun problème. Le problème apparaît quand vous construisez toute votre architecture de navigation autour des fragments.
Soyons honnêtes : en 2025, l'History API et le routing moderne (Next.js, Nuxt) sont infiniment plus fiables pour le SEO. Si vous démarrez un projet, n'utilisez les fragments que pour les ancres — jamais pour la navigation principale.
Impact pratique et recommandations
Que faut-il faire si votre site utilise déjà des fragments pour la navigation ?
Premier réflexe : testez le rendu côté Google. L'outil de test d'URL dans Search Console vous montre exactement ce que Googlebot voit après exécution du JavaScript. Si votre contenu n'apparaît pas dans le rendu, vous avez un problème.
Ensuite, vérifiez vos logs serveur. Les pages avec fragments génèrent-elles des requêtes distinctes côté bot ? Si oui, combien de temps entre le premier hit et le rendu complet ? Plus de 5 secondes = zone rouge.
Quelles alternatives concrètes mettre en place ?
La solution la plus propre : migrer vers l'History API. Vous gardez une navigation fluide côté client, mais avec des URLs propres que Google comprend sans avoir à exécuter quoi que ce soit.
Si une migration complète n'est pas possible à court terme, implémentez du Server-Side Rendering (SSR) ou du Static Site Generation (SSG). Le contenu critique doit être présent dans le HTML initial — le JavaScript ne fait alors que l'enrichir.
- Auditer toutes les URLs utilisant des fragments avec fonction JavaScript
- Tester le rendu Googlebot via Search Console pour chaque type de page
- Vérifier que le contenu principal est accessible sans exécution JS
- Implémenter des balises canoniques si plusieurs fragments pointent vers le même contenu
- Monitorer le budget de crawl — les pages à rendu JS coûtent plus cher
- Privilégier l'History API pour toute nouvelle implémentation
- Documenter clairement quel contenu dépend des fragments
❓ Questions frequentes
Les ancres classiques (#section) sont-elles concernées par cette exception ?
Mon SPA en React utilise HashRouter — est-ce un problème pour le SEO ?
Comment vérifier si Google traite correctement mes fragments avec JavaScript ?
Le budget de crawl est-il impacté par cette exception ?
Peut-on utiliser des fragments pour du contenu secondaire sans risque ?
🎥 De la même vidéo 2
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/10/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.