Declaration officielle
Ce qu'il faut comprendre
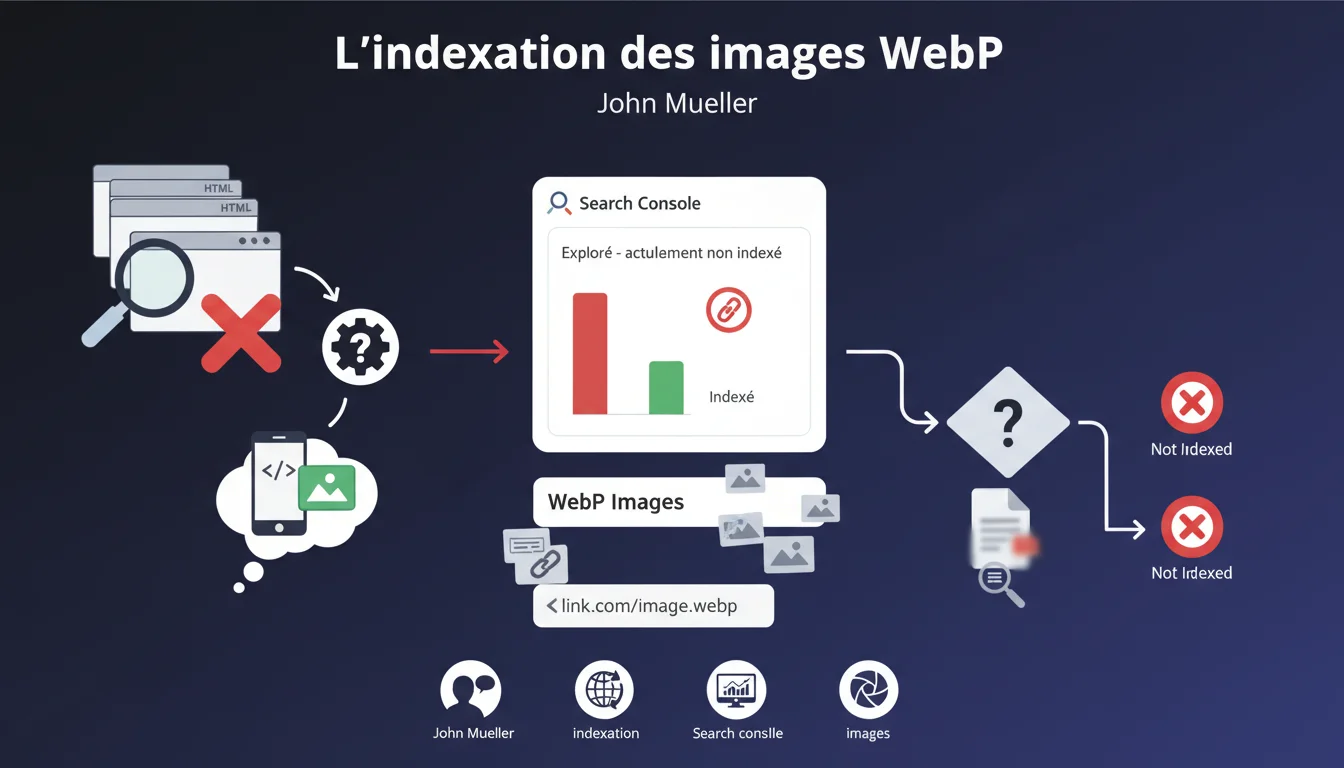
Quelle est l'origine de ce problème d'indexation des images WebP ?
Google rencontre parfois des difficultés pour identifier la nature réelle d'une URL avant de l'explorer. Lorsqu'une URL pointe vers une image WebP mais ressemble à une page HTML classique, le robot peut la traiter comme une page web.
Ce n'est qu'après l'exploration que Google réalise qu'il s'agit d'une image et non d'une page. L'URL apparaît alors dans le rapport « Exploré - actuellement non indexé » de la Search Console, ce qui peut créer de la confusion.
Dans quelles situations ce problème se manifeste-t-il ?
Le problème survient principalement quand l'extension du fichier n'est pas explicite dans l'URL. Par exemple, une URL avec des paramètres ou une réécriture d'URL peut masquer la véritable nature de la ressource.
Les systèmes de gestion de médias dynamiques ou les CDN qui génèrent des URLs complexes sont particulièrement concernés. Google suit alors un lien pensant trouver du contenu HTML.
Faut-il s'inquiéter de ce comportement ?
Ce comportement représente une erreur d'identification de Google, mais elle est généralement rare selon les observations. Elle n'impacte pas négativement votre SEO puisque ces images ne devraient de toute façon pas être indexées comme des pages.
- Les images WebP ne doivent pas être indexées comme des pages HTML
- Le rapport « Exploré - non indexé » peut inclure des images si leur URL prête à confusion
- Cette situation reflète une erreur d'analyse de Google avant l'exploration
- Le problème est détecté après exploration, d'où l'absence d'indexation finale
- L'impact SEO réel est négligeable pour la plupart des sites
Avis d'un expert SEO
Cette situation révèle-t-elle un problème d'architecture plus profond ?
Bien que Google minimise l'importance de ce phénomène, sa présence dans vos rapports peut indiquer des faiblesses structurelles. Des URLs ambiguës pour vos ressources médias suggèrent une architecture peu optimale.
Dans mon expérience, les sites affichant massivement ce comportement souffrent souvent de problèmes de crawl budget. Google perd du temps à explorer des ressources qu'il ne devrait même pas considérer comme des pages potentielles.
Quels risques réels cette confusion génère-t-elle pour votre SEO ?
Le risque principal n'est pas l'absence d'indexation des images, mais la consommation inutile de ressources d'exploration. Chaque URL explorée par erreur réduit la capacité de Google à crawler vos vraies pages.
Sur les gros sites avec des milliers d'images, cela peut représenter une perte significative d'efficacité. Les pages importantes risquent d'être explorées moins fréquemment si Google s'enlise dans vos assets médias.
Comment interpréter ce comportement dans une stratégie d'indexation globale ?
Cette déclaration confirme que Google prend des décisions d'exploration basées sur des hypothèses avant même d'accéder au contenu. Cela renforce l'importance de la clarté sémantique de vos URLs.
Les sites qui optimisent leurs structures d'URLs avec des extensions claires et des chemins logiques facilitent le travail de Google. Cette efficacité se traduit par une meilleure allocation du crawl budget vers le contenu stratégique.
Impact pratique et recommandations
Comment vérifier si votre site est concerné par ce problème ?
Rendez-vous dans la Search Console, section « Indexation des pages », et filtrez sur le statut « Exploré - actuellement non indexé ». Triez les URLs pour identifier celles contenant des extensions d'images (.webp, .jpg, .png).
Utilisez un export CSV pour analyser le volume. Si plus de 5% de vos URLs non indexées sont des images, vous devez agir rapidement pour optimiser votre architecture.
Quelles actions concrètes mettre en place pour résoudre cette situation ?
La solution la plus efficace consiste à clarifier vos structures d'URLs. Assurez-vous que toutes vos URLs d'images contiennent explicitement l'extension du fichier (.webp, .jpg, etc.).
Implémentez un fichier robots.txt approprié pour bloquer l'exploration des répertoires contenant uniquement des ressources médias. Utilisez la directive Disallow pour les dossiers /images/, /media/, /assets/ selon votre architecture.
- Auditez votre Search Console pour identifier les images dans « Exploré - non indexé »
- Vérifiez que vos URLs d'images contiennent des extensions explicites
- Utilisez robots.txt pour bloquer l'exploration des répertoires médias non stratégiques
- Configurez des règles de réécriture d'URL qui préservent les extensions de fichiers
- Implémentez un sitemap images séparé pour guider Google vers vos visuels stratégiques
- Surveillez régulièrement l'évolution du rapport pour mesurer l'efficacité des corrections
- Optimisez vos balises canoniques pour éviter toute ambiguïté de contenu
Quand faut-il envisager un accompagnement spécialisé ?
Si votre site gère des milliers d'images avec des URLs générées dynamiquement, la résolution de ce problème peut s'avérer complexe. Les modifications touchent souvent plusieurs couches techniques : CDN, CMS, serveur web.
L'optimisation du crawl budget et de l'architecture d'URLs requiert une expertise approfondie pour éviter les erreurs critiques. Une mauvaise configuration du robots.txt ou des redirections peut gravement impacter votre visibilité.
💬 Commentaires (0)
Soyez le premier à commenter.