Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi l'API Search Console contient-elle plus de données que l'interface utilisateur ?
- □ Pourquoi Search Console plafonne-t-elle vos rapports d'indexation à 1000 lignes ?
- □ Pourquoi Google a-t-il multiplié par 5 la rétention de données dans Search Console ?
- □ Pourquoi Google refuse-t-il d'indexer certaines de vos pages ?
- □ Faut-il vraiment corriger toutes les notifications de Google Search Console ?
- □ Faut-il vraiment corriger toutes les erreurs 404 détectées dans Search Console ?
- □ Pourquoi Google refuse-t-il de diagnostiquer vos problèmes de ranking ?
- □ Search Console Insights : Google propose-t-il enfin un outil SEO pour non-techniciens ?
- □ Pourquoi l'intégration BigQuery de Search Console change-t-elle la donne pour l'analyse SEO avancée ?
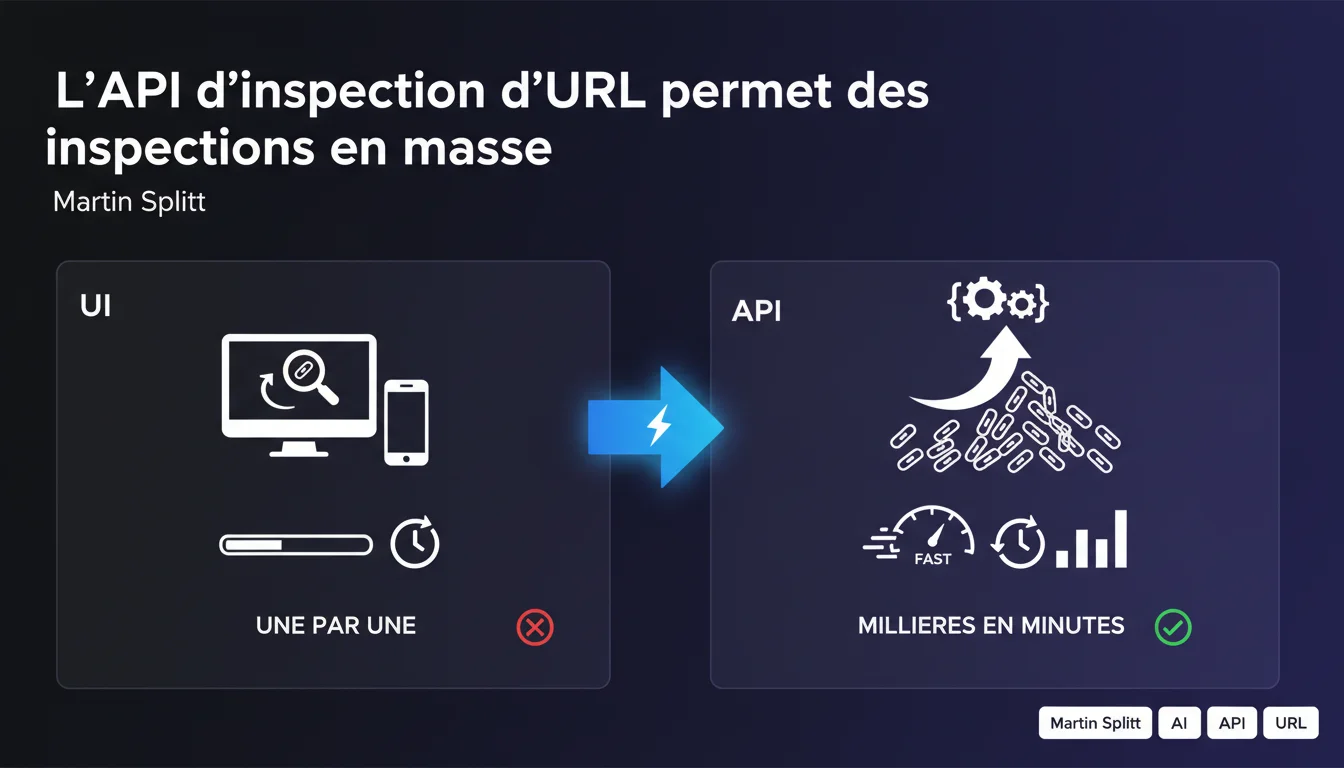
Google confirme que son API d'inspection d'URL permet d'automatiser des milliers de vérifications en quelques minutes, là où l'interface Search Console impose un processus manuel unitaire. Pour les sites de plusieurs milliers de pages, c'est un gain de temps considérable — mais encore faut-il savoir exploiter cette API correctement.
Ce qu'il faut comprendre
Qu'est-ce que l'API d'inspection d'URL et en quoi diffère-t-elle de l'outil Search Console ?
L'outil d'inspection d'URL dans la Search Console classique permet de vérifier l'indexabilité d'une page précise : Google renvoie des informations sur le dernier crawl, les erreurs rencontrées, le statut d'indexation. Le problème ? On ne peut soumettre qu'une URL à la fois.
L'API d'inspection d'URL offre exactement les mêmes données, mais via un accès programmatique. Résultat : on peut automatiser les requêtes et interroger des milliers d'URL en quelques minutes. Pour un site e-commerce avec 50 000 fiches produits, la différence est brutale.
Pourquoi Google met-il en avant cette API maintenant ?
La déclaration de Martin Splitt intervient dans un contexte où de plus en plus de sites dépassent les dizaines de milliers de pages. Les outils manuels deviennent impraticables à cette échelle.
Google pousse clairement les SEO à adopter des workflows automatisés. Cela permet aussi à Google de réduire la charge sur l'interface utilisateur de la Search Console, qui reste une application web avec ses limites techniques.
Quelles données peut-on extraire via cette API ?
- Statut d'indexation : la page est-elle indexée, et si non, pourquoi ?
- Dernière date de crawl : quand Googlebot est-il passé pour la dernière fois ?
- Couverture d'index : erreurs d'exploration, redirections, canonicales détectées
- Résultat du rendu JavaScript : la page est-elle correctement interprétée côté client ?
- Problèmes d'ergonomie mobile et Core Web Vitals dans certains cas
Avis d'un expert SEO
Cette API est-elle vraiment utilisable en production ou reste-t-elle un gadget technique ?
Soyons honnêtes : beaucoup de SEO connaissent l'existence de cette API sans jamais l'avoir implémentée. Pourquoi ? Parce qu'elle nécessite des compétences en développement backend — authentification OAuth, gestion des quotas, parsing JSON. Ce n'est pas un clic dans une interface.
En revanche, pour les équipes techniques ou les agences qui gèrent des sites à fort volume, c'est un outil indispensable. On peut croiser ces données avec des logs serveur, des sitemaps XML, ou des crawls Screaming Frog pour identifier les pages orphelines, les contenus bloqués par le robots.txt mais crawlés quand même, etc.
Quelles limites faut-il connaître avant de se lancer ?
Google impose un quota quotidien : 2 000 requêtes par jour et par propriété Search Console. Pour un site de 100 000 URLs, cela signifie 50 jours pour tout auditer. Ce n'est pas négligeable.
Autre point : l'API renvoie les données du dernier crawl connu. Si Googlebot n'est pas repassé depuis 3 semaines sur une page, l'API te donnera des infos vieilles de 3 semaines. [À vérifier] : aucune documentation Google ne précise si on peut forcer un re-crawl via l'API elle-même — la fonctionnalité "Demander une indexation" reste manuelle.
Dans quels cas cette API ne suffit-elle pas ?
L'API d'inspection d'URL ne remplace pas un crawler complet. Elle ne te dira pas quelles pages existent sur ton site — elle te donne juste l'avis de Google sur les URLs que tu lui soumets.
Si tu veux identifier toutes les pages orphelines, les profondeurs de crawl excessives, ou les boucles de redirections internes, tu as encore besoin d'un outil comme Screaming Frog, OnCrawl, ou Botify. L'API vient en complément, pas en remplacement.
Impact pratique et recommandations
Que faut-il faire concrètement pour exploiter cette API ?
Première étape : activer l'API URL Inspection dans la console Google Cloud, créer un projet, générer des credentials OAuth2. Ensuite, tu devras coder (ou faire coder) un script qui authentifie la requête et interroge l'endpoint https://searchconsole.googleapis.com/v1/urlInspection/index:inspect.
Les langages les plus utilisés sont Python (avec la librairie google-api-python-client) et Node.js. Des exemples de code existent dans la documentation officielle, mais ils restent très basiques — il faut les adapter à ton infrastructure.
Quelles erreurs éviter lors de l'implémentation ?
- Ne pas gérer correctement les quotas : si tu envoies 3 000 requêtes d'un coup, Google te bloque
- Oublier de filtrer les URLs en double : pas la peine d'interroger 5 fois la même page
- Ne pas logger les résultats : tu perds toute traçabilité si tu ne stockes pas les réponses JSON
- Ignorer les erreurs 429 (rate limiting) : il faut prévoir des pauses et des retry automatiques
- Croire que l'API force un re-crawl : non, elle ne fait que renvoyer les données du dernier passage de Googlebot
Comment vérifier que mon implémentation fonctionne correctement ?
Commence par un test sur 10-20 URLs représentatives : des pages indexées, d'autres bloquées, des redirections. Compare les résultats de l'API avec ce que tu vois dans l'interface Search Console manuelle.
Ensuite, mets en place un système de monitoring : si ton script tourne en cron quotidien, tu veux être alerté en cas d'échec d'authentification, de quota dépassé, ou de changement brutal dans le taux d'indexation.
❓ Questions frequentes
L'API d'inspection d'URL consomme-t-elle du crawl budget ?
Peut-on utiliser cette API sur un site dont on n'est pas propriétaire dans la Search Console ?
Quelle est la différence entre l'API d'inspection d'URL et l'Indexing API ?
Les données renvoyées par l'API sont-elles en temps réel ?
Combien de requêtes peut-on faire par jour avec cette API ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.