Declaration officielle
Ce qu'il faut comprendre
Pourquoi l'ordre d'indexation ne détermine-t-il pas l'originalité du contenu ?
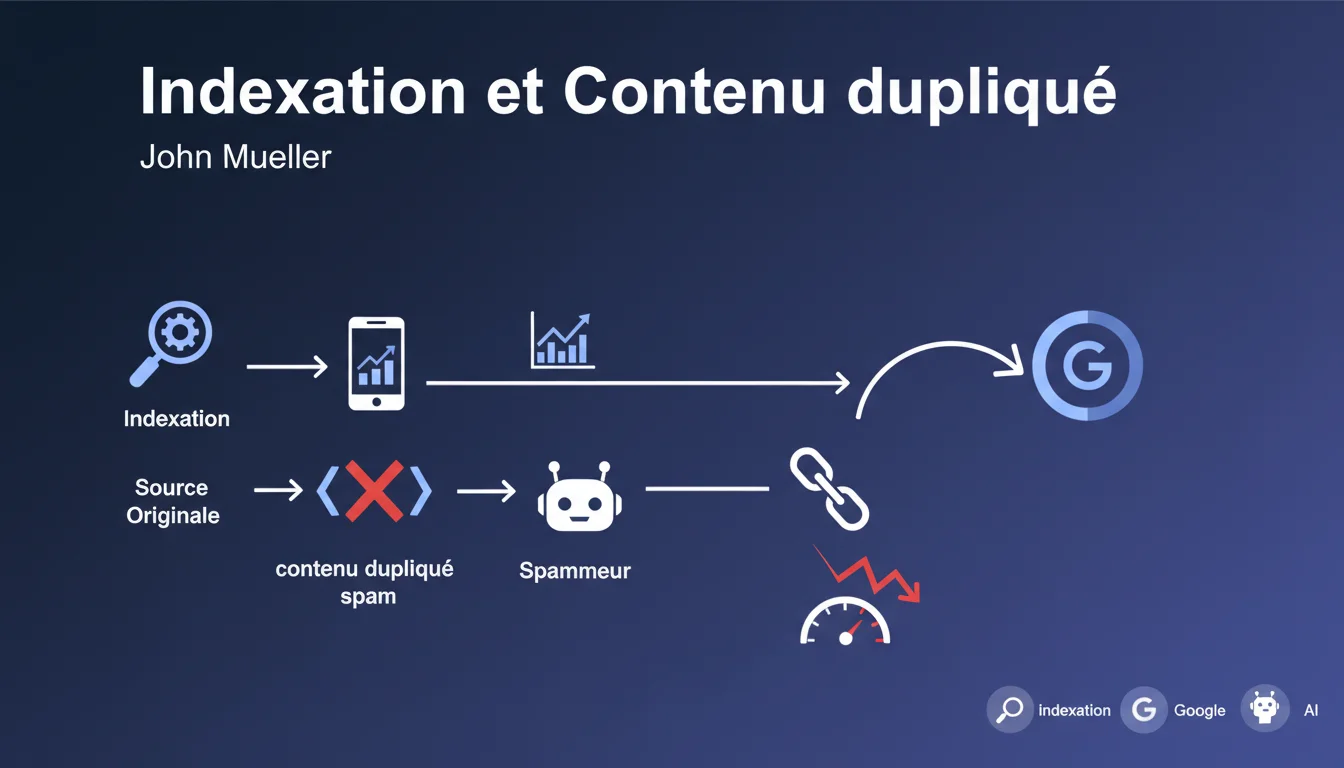
Google a clarifié une idée reçue importante : être indexé en premier ne fait pas de vous l'auteur original aux yeux du moteur de recherche. Si un scrapers ou un plagiaire copie votre contenu et que Google l'indexe avant votre propre page, cela ne signifie pas qu'il sera considéré comme la source canonique.
Cette déclaration est fondamentale car elle révèle que Google utilise des algorithmes sophistiqués pour identifier la véritable source d'un contenu, au-delà du simple critère temporel d'indexation. Le moteur déploie des signaux multiples pour déterminer l'originalité.
Quels critères Google utilise-t-il pour identifier le contenu original ?
Google s'appuie sur plusieurs signaux de confiance et d'autorité pour distinguer l'original de la copie. Le PageRank de la page est l'un des critères confirmés : une page avec une autorité établie aura plus de chances d'être reconnue comme source originale.
D'autres facteurs entrent probablement en jeu, comme l'historique du domaine, la fréquence de publication, les signaux d'auteur, ou encore les patterns de comportement du site. Google garde volontairement le silence sur l'ensemble de ces critères pour éviter les manipulations.
Que se passe-t-il en l'absence de balise canonical ?
Lorsqu'aucune balise canonical n'est spécifiée, Google doit arbitrer seul entre les différentes versions d'un même contenu. C'est dans ce contexte que les algorithmes de détection d'originalité prennent toute leur importance.
Le moteur va analyser l'ensemble des signaux disponibles pour choisir quelle URL afficher dans les résultats de recherche. Cette décision algorithmique peut parfois surprendre, d'où l'importance de comprendre les mécanismes sous-jacents.
- L'ordre d'indexation n'est pas le critère déterminant pour l'originalité
- Le PageRank et l'autorité de la page jouent un rôle majeur dans la détection
- Google utilise de multiples signaux non communiqués publiquement
- Les balises canonical permettent de guider explicitement Google
- La vitesse d'indexation ne protège pas contre le plagiat
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, cette affirmation correspond parfaitement aux observations des professionnels SEO depuis des années. De nombreux cas documentés montrent des sites autoritaires retrouvant leur statut d'original même après avoir été scrapés et indexés en second.
J'ai personnellement constaté que les sites avec un profil de liens solide et un historique établi récupèrent généralement leur position d'auteur original en quelques jours ou semaines. Les algorithmes de Google semblent effectuer des réévaluations continues pour affiner leur jugement.
Quelles nuances importantes faut-il apporter à cette affirmation ?
La principale nuance concerne le délai de réaction de Google. Même si l'algorithme finit par identifier le bon original, il peut y avoir une période transitoire où le scrapers bénéficie d'un avantage injuste. Pendant ce laps de temps, votre contenu peut être pénalisé.
Autre point critique : cette protection algorithmique fonctionne mieux pour les sites établis avec de l'autorité. Un nouveau site sans historique ni backlinks aura plus de difficultés à prouver son originalité face à un plagiaire disposant d'un domaine plus ancien ou mieux référencé.
Dans quels cas cette détection automatique peut-elle échouer ?
Les situations problématiques surviennent principalement avec les nouveaux sites sans autorité établie. Si vous lancez un blog et qu'un site puissant copie immédiatement votre contenu, Google peut avoir du mal à trancher, du moins initialement.
Les contenus syndiqués ou republiés légitimement posent aussi des défis. Sans balises canonical appropriées, Google peut choisir la version syndiquée plutôt que l'originale si elle apparaît sur un site plus autoritaire. C'est pourquoi les accords de syndication doivent toujours inclure des directives techniques claires.
Impact pratique et recommandations
Que faut-il mettre en place concrètement pour protéger son contenu ?
La prévention reste votre meilleure défense. Utilisez systématiquement des balises canonical sur vos propres pages pour éliminer toute ambiguïté. Construisez progressivement l'autorité de votre domaine via une stratégie de netlinking cohérente.
Mettez en place une surveillance du scraping avec des outils comme Copyscape ou des alertes Google pour détecter rapidement les copies. Plus vous intervenez vite, moins les dégâts seront importants. Considérez l'utilisation de flux RSS tronqués pour limiter l'automatisation du vol de contenu.
Structurez votre contenu avec des éléments d'identification uniques : citations internes, liens vers vos autres articles, éléments de marque. Ces signaux aident Google à tracer l'origine du contenu.
Quelles erreurs critiques faut-il absolument éviter ?
Ne négligez jamais l'implémentation correcte des balises canonical, même pour vos propres pages. Une canonical mal configurée peut indiquer à Google qu'une autre version est l'originale, vous tirant une balle dans le pied.
Évitez de republier massivement votre propre contenu sur d'autres plateformes sans précautions. Chaque republication doit pointer vers l'original via une canonical, sinon vous créez vous-même de la confusion pour les algorithmes.
Ne sous-estimez pas l'importance de la vitesse d'indexation malgré tout. Même si ce n'est pas le seul critère, soumettre rapidement vos URLs via Search Console et avoir un site bien crawlable donne un avantage dans la course contre les scrapers.
Comment vérifier et optimiser sa protection contre le contenu dupliqué ?
Utilisez Search Console pour identifier les problèmes de duplication que Google a détectés. La section « Couverture » et les rapports sur les pages exclues révèlent souvent des surprises sur les URLs considérées comme duplicatas.
Effectuez des recherches régulières avec des extraits uniques de vos contenus entre guillemets pour repérer les copies. Surveillez particulièrement vos articles les plus performants, car ce sont les cibles privilégiées des scrapers.
- Implémenter des balises canonical auto-référencées sur toutes vos pages de contenu
- Construire progressivement l'autorité de domaine via des backlinks de qualité
- Mettre en place une surveillance automatisée du scraping avec des alertes
- Soumettre les nouveaux contenus rapidement via Search Console
- Utiliser des flux RSS tronqués pour limiter le scraping automatisé
- Intégrer des éléments de marque uniques dans chaque contenu
- Vérifier régulièrement les rapports de duplication dans Search Console
- Agir rapidement en cas de détection de copie (DMCA si nécessaire)
- Auditer la configuration technique des canonicals sur l'ensemble du site
💬 Commentaires (0)
Soyez le premier à commenter.