Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Comment Google comptabilise-t-il les impressions et clics dans les People Also Ask ?
- □ Les liens depuis un sous-domaine vers le domaine principal ont-ils moins de valeur en SEO ?
- □ Tous les liens dans Search Console sont-ils vraiment utiles pour votre SEO ?
- □ Une page AMP invalide peut-elle quand même être indexée par Google ?
- □ Les liens massifs en footer tuent-ils vraiment le contexte de votre site ?
- □ Faut-il désactiver les liens automatiques pour améliorer son SEO ?
- □ Le texte caché est-il encore un problème pour le SEO ?
- □ Quelques liens d'affiliation sans attribut peuvent-ils vraiment échapper à toute pénalité ?
- □ Pourquoi vos images n'apparaissent-elles jamais dans Google Images malgré un bon SEO ?
- □ Pourquoi Google insiste-t-il pour que les sitemaps ne soient jamais votre seul filet de sécurité ?
- □ Faut-il vraiment utiliser des canonicals sur vos pages de recherche interne filtrées ?
- □ Les Core Web Vitals peuvent-ils vraiment faire chuter votre positionnement de 48 places ?
- □ Pourquoi le validateur schema.org contredit-il les outils de Google ?
- □ Pourquoi Google ignore-t-il certains paramètres d'URL de langue ?
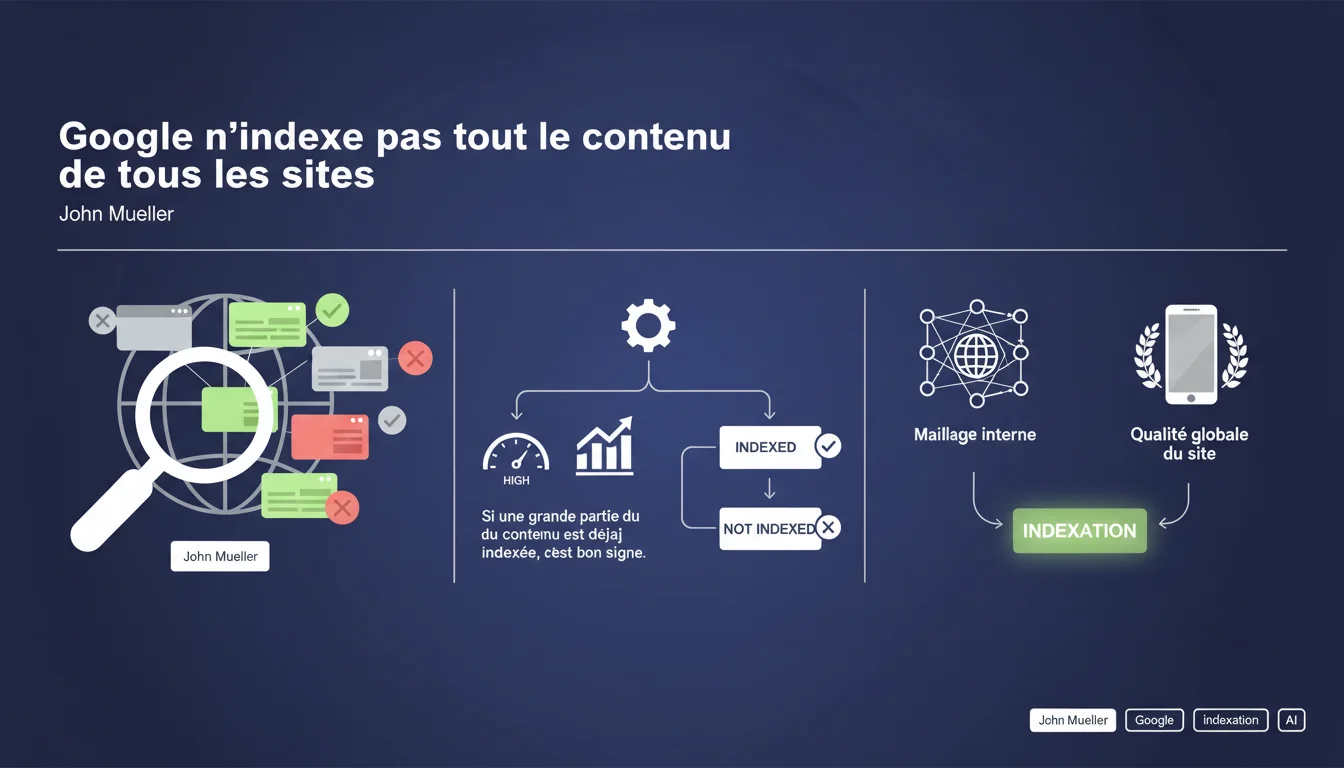
Google ne crawle ni n'indexe automatiquement toutes les pages d'un site. Les statuts 'découvert, non exploré' ou 'exploré, non indexé' ne signalent pas forcément un bug technique — ils reflètent souvent un choix délibéré de l'algorithme. Autrement dit : Google décide ce qui mérite ou non d'être indexé, indépendamment de votre volonté.
Ce qu'il faut comprendre
Google fait-il un tri sélectif dans vos contenus ?
Oui, et c'est même le principe de base. Google n'a jamais promis d'indexer l'intégralité du web. Chaque page passe par un filtre : est-elle utile ? Apporte-t-elle quelque chose d'unique ? Le crawl et l'indexation ont un coût — serveurs, énergie, stockage. Google optimise ses ressources en priorisant les contenus qu'il juge pertinents pour ses utilisateurs.
Dans la Search Console, vous voyez deux statuts qui traduisent ce tri. « Découvert, non exploré » : Google connaît l'URL mais n'a pas encore décidé si elle mérite un crawl. « Exploré, non indexé » : la page a été visitée, analysée, puis écartée de l'index. Dans les deux cas, ce n'est pas nécessairement un drame technique.
Quand faut-il s'inquiéter de ces statuts ?
Ça dépend du type de page concernée. Si vos pages stratégiques — celles qui génèrent du trafic ou des conversions — restent bloquées pendant des semaines, il y a un problème. Mais si Google ignore vos pages de tags redondantes, vos archives mensuelles ou vos filtres produits avec deux variantes de couleur, c'est plutôt bon signe : l'algorithme fait son travail de nettoyage.
Le vrai enjeu, c'est de comprendre pourquoi Google fait ce choix. Est-ce un signal de qualité insuffisante ? Un souci de canonicalisation ? Un crawl budget mal réparti ? Ou simplement du contenu peu différencié ?
Que signifie « plusieurs semaines » dans cette déclaration ?
John Mueller reste flou — et c'est probablement volontaire. « Plusieurs semaines » peut signifier 3 semaines comme 12. Aucun délai précis n'est donné, ce qui laisse Google libre d'ajuster ses critères selon les sites, les secteurs, l'actualité.
Ce qu'il faut retenir : ne paniquez pas au bout de 7 jours. Mais si après 2-3 mois vos pages clés n'apparaissent toujours pas, il est temps d'investiguer sérieusement.
- Google ne crawle ni n'indexe tout — c'est un choix stratégique de l'algorithme, pas un bug
- Les statuts « découvert, non exploré » ou « exploré, non indexé » ne sont pas des alarmes rouges par défaut
- Prioriser les pages stratégiques : vérifiez d'abord que vos contenus à forte valeur ajoutée sont bien indexés
- Aucun délai officiel n'est communiqué — « plusieurs semaines » reste une formule vague
- Le tri de Google repose sur des critères de qualité, d'unicité et d'utilité pour l'utilisateur final
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. Depuis des années, on constate que Google indexe de moins en moins de pages, même sur des sites techniquement propres. Les gros sites de contenu — médias, e-commerce, annuaires — voient des pans entiers de leurs pages écartés de l'index, sans message d'erreur dans la Search Console.
Ce que Mueller confirme ici, c'est que ce n'est pas un bug, mais une politique assumée. Google privilégie la qualité à la quantité. Le problème, c'est qu'aucun critère précis n'est donné. On sait que la duplication, la faible profondeur de contenu, l'absence de backlinks jouent — mais dans quelle proportion ? [À vérifier] : les seuils exacts restent opaques.
Quelles nuances faut-il apporter à cette déclaration ?
Mueller parle de « choix d'indexation », mais il omet un détail crucial : Google ne distingue pas toujours entre « pas intéressant » et « pas encore prioritaire ». Une page peut rester en « découvert, non exploré » simplement parce que le crawl budget est saturé ailleurs, pas parce qu'elle est mauvaise.
Autre point : dire que « ce n'est pas un problème technique » peut décourager certains de chercher plus loin. Or, dans bien des cas, un maillage interne défaillant, des balises canonical mal posées ou un robots.txt trop restrictif bloquent réellement l'indexation. Ne prenez pas cette déclaration comme un blanc-seing pour ignorer vos fondamentaux techniques.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vos pages stratégiques — homepage, catégories principales, articles piliers — restent non indexées au-delà de 4 semaines, ce n'est plus un « choix d'indexation » normal. C'est un signal d'alarme. Soit Google ne les trouve pas (problème de crawl), soit il les juge non pertinentes (problème de qualité ou de cannibalisation).
Même constat pour les sites récents ou en refonte : si Google ne crawle rien pendant des semaines, il ne s'agit pas d'un tri sélectif, mais d'un défaut de découverte. Dans ce cas, un sitemap XML bien construit, des backlinks de qualité et un maillage interne solide restent indispensables.
Impact pratique et recommandations
Que faut-il faire concrètement si vos pages restent non indexées ?
D'abord, identifiez quelles pages sont concernées. Toutes les URLs ne méritent pas le même traitement. Si Google ignore vos pages de mentions légales ou vos filtres produits redondants, laissez tomber. Si ce sont vos fiches produits bestsellers ou vos articles de fond, il faut agir.
Ensuite, croisez les données : Search Console, logs serveur, outils de crawl. Est-ce que Google découvre bien ces pages ? Si elles n'apparaissent nulle part, c'est un souci de maillage interne ou de sitemap. Si elles sont crawlées mais non indexées, c'est un signal qualité : contenu faible, duplication, cannibalisation.
Quelles erreurs éviter pour maximiser vos chances d'indexation ?
Ne submergez pas Google de pages inutiles. Moins, c'est mieux — surtout si votre crawl budget est limité. Évitez les pages paginées infinies, les tags générés automatiquement, les variantes produit quasi-identiques. Chaque URL doit avoir une vraie raison d'exister.
Autre piège classique : forcer l'indexation via l'outil d'inspection d'URL pour des dizaines de pages. Google tolère mal cette pratique à grande échelle. Privilégiez un sitemap XML propre, un maillage interne cohérent et des backlinks naturels pour signaler vos priorités.
Comment vérifier que votre site est bien optimisé pour l'indexation sélective de Google ?
Auditez régulièrement vos pages non indexées dans la Search Console. Classez-les par type : stratégiques, secondaires, inutiles. Pour les stratégiques non indexées, vérifiez la qualité du contenu, l'unicité, la profondeur. Un texte de 150 mots dupliqué sur 3 pages similaires n'a aucune chance.
Analysez aussi votre maillage interne. Les pages importantes doivent être accessibles en 2-3 clics maximum depuis la homepage, avec des ancres contextuelles et des liens depuis des pages déjà bien rankées.
- Identifiez les pages stratégiques non indexées via la Search Console
- Croisez avec vos logs serveur pour vérifier si Google les crawle réellement
- Éliminez les pages redondantes, faibles ou dupliquées qui saturent votre crawl budget
- Renforcez le maillage interne vers vos contenus prioritaires
- Améliorez la qualité et l'unicité des pages écartées de l'index
- Utilisez un sitemap XML propre et à jour, sans URLs inutiles
- Obtenez des backlinks de qualité vers vos pages clés pour signaler leur importance
- Surveillez l'évolution de l'indexation sur plusieurs semaines, sans paniquer au bout de 7 jours
❓ Questions frequentes
Combien de temps faut-il attendre avant de s'inquiéter qu'une page ne soit pas indexée ?
Le statut « exploré, non indexé » signifie-t-il que ma page est de mauvaise qualité ?
Peut-on forcer Google à indexer une page via l'outil d'inspection d'URL ?
Est-ce grave si Google n'indexe pas mes pages de tags ou mes archives ?
Comment savoir si le problème vient d'un manque de crawl budget ou d'un contenu faible ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.