Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Faut-il vraiment optimiser les Core Web Vitals pour ranker sur Google ?
- □ Faut-il vraiment arrêter de sur-optimiser les Core Web Vitals ?
- □ Faut-il vraiment réduire l'usage de JavaScript pour améliorer votre SEO ?
- □ Comment optimiser vos images pour améliorer votre SEO technique ?
- □ La vitesse du site est-elle vraiment un facteur de classement Google ?
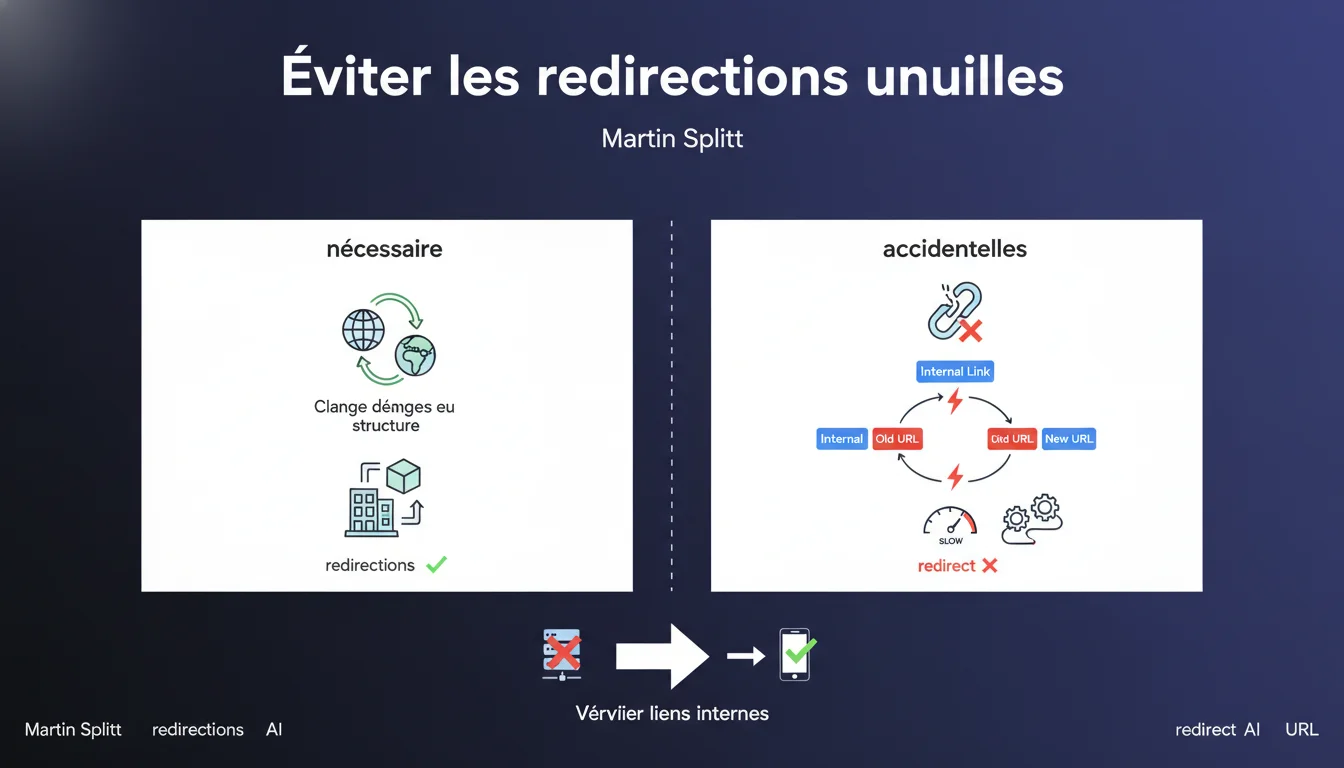
Martin Splitt rappelle que les redirections accidentelles ralentissent le crawl et l'indexation. Les liens internes doivent pointer directement vers les URLs finales, pas vers des redirections. Seules les redirections liées à des migrations ou restructurations sont justifiées — le reste est du gaspillage de crawl budget.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur les redirections « inutiles » ?
Chaque redirection impose un aller-retour réseau supplémentaire. Le bot doit interroger le serveur, recevoir un code 301 ou 302, puis requêter l'URL de destination. Ce cycle consomme du crawl budget, cette ressource limitée que Google alloue à chaque site.
Sur un petit site de 50 pages, l'impact reste négligeable. Mais dès qu'on dépasse quelques milliers d'URLs — ou qu'on opère dans un secteur concurrentiel où chaque milliseconde compte — ces allers-retours s'accumulent et ralentissent la découverte de nouveaux contenus.
Qu'est-ce qu'une redirection « accidentelle » concrètement ?
Splitt vise les redirections non intentionnelles : un lien interne qui pointe vers une ancienne URL alors que la nouvelle existe, une canonique mal configurée qui force un passage par une redirection, un système de gestion de contenu qui génère des URLs temporaires redirigées automatiquement.
Typiquement, c'est le CMS qui ajoute un slash final par défaut, ou le développeur qui oublie de mettre à jour les liens après une refonte. Résultat : des chaînes de redirections inutiles que personne n'a voulu créer mais que personne ne détecte.
Les redirections nécessaires restent-elles acceptables ?
Oui. Une migration de domaine, un changement de structure d'URLs, une fusion de contenus — tout ça justifie des redirections 301. Google ne dit pas « zéro redirection », il dit « zéro redirection accidentelle ».
La distinction est importante. Si tu restructures ton site et que tu mappes proprement tes anciennes URLs vers les nouvelles, c'est légitime. Mais une fois la migration terminée, tes liens internes doivent pointer directement vers les nouvelles URLs, pas vers les anciennes qui redirigent.
- Les redirections consomment du crawl budget et ralentissent l'indexation
- Une redirection « accidentelle » est une redirection non intentionnelle créée par erreur technique ou négligence
- Les migrations et restructurations justifient des redirections, mais les liens internes doivent être mis à jour ensuite
- Les chaînes de redirections (A → B → C) sont particulièrement coûteuses et doivent être évitées
Avis d'un expert SEO
Cette consigne est-elle cohérente avec les observations terrain ?
Absolument. Les audits SEO révèlent régulièrement des chaînes de redirections stupides : A redirige vers B qui redirige vers C, alors qu'un simple A → C suffirait. Ou pire, des liens internes qui pointent vers des URLs redirigées depuis des années.
Ce qui coince, c'est que Google ne quantifie jamais l'impact réel. « Éviter des allers-retours réseau supplémentaires », OK — mais combien de redirections avant que ça devienne critique ? 10 ? 100 ? 1 000 ? [A vérifier] en fonction de l'autorité du site et de la fréquence de crawl.
Quelles nuances faut-il apporter à cette déclaration ?
Première nuance : toutes les redirections ne se valent pas. Une redirection servie via CDN en edge avec une latence de 5 ms n'a pas le même coût qu'une redirection dynamique générée par un serveur d'origine surchargé qui prend 300 ms à répondre.
Deuxième nuance : les redirections JavaScript ou meta-refresh sont encore plus toxiques que les 301/302 classiques. Elles forcent Google à exécuter du JS ou attendre un délai avant de découvrir la vraie destination. Si Splitt parle de « redirections », il faut comprendre toutes les formes de redirections, pas juste les codes HTTP.
Dans quels cas cette règle ne s'applique-t-elle pas strictement ?
Sur les très gros sites e-commerce avec des millions d'URLs générées dynamiquement, il est parfois techniquement impossible de mettre à jour tous les liens internes en temps réel. Les facettes de filtres, les URLs de session, les paramètres de tracking — tout ça peut créer des redirections « accidentelles » en masse.
Dans ce contexte, la vraie priorité est de nettoyer les redirections sur les pages stratégiques : catégories principales, produits phares, landing pages SEO. Le reste peut attendre un chantier technique plus global — mais il faut prioriser, pas ignorer.
Impact pratique et recommandations
Comment détecter les redirections accidentelles sur votre site ?
Commence par un crawl complet avec Screaming Frog, Oncrawl ou Botify. Configure le crawler pour suivre les redirections et identifier les chaînes (A → B → C). Exporte ensuite la liste des URLs avec code 301/302 et croise-la avec tes liens internes.
Ensuite, vérifie les redirections JavaScript et meta-refresh avec un crawler capable de rendre le JS. Chrome DevTools + Network tab te permet aussi de détecter manuellement les redirections cachées sur des pages stratégiques.
Que faut-il faire concrètement pour corriger le problème ?
Une fois les redirections identifiées, mets à jour les liens internes pour qu'ils pointent directement vers l'URL finale. Si tu utilises un CMS, vérifie les templates et les widgets qui génèrent automatiquement des liens — c'est souvent là que se cache le problème.
Pour les chaînes de redirections, simplifie-les en redirigeant directement A → C. Et si une redirection n'a plus de raison d'exister (migration terminée depuis 2 ans, par exemple), envisage de la supprimer — à condition que l'ancienne URL ne reçoive plus de trafic ni de backlinks actifs.
- Crawler le site pour identifier toutes les redirections 301/302 et les chaînes multiples
- Vérifier les redirections JavaScript et meta-refresh avec un outil qui rend le JS
- Mettre à jour les liens internes pour qu'ils pointent directement vers les URLs finales
- Simplifier les chaînes de redirections (A → B → C devient A → C)
- Auditer les templates CMS qui génèrent automatiquement des liens
- Surveiller régulièrement les nouvelles redirections introduites lors des déploiements
❓ Questions frequentes
Les redirections 301 consomment-elles autant de crawl budget que les 302 ?
Faut-il supprimer les redirections après une migration si elles reçoivent encore du trafic ?
Les redirections JavaScript sont-elles aussi problématiques que les redirections HTTP ?
Combien de temps après une migration peut-on retirer les redirections 301 ?
Comment savoir si mes redirections impactent réellement mon crawl budget ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/09/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.