Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Les erreurs 404 et redirections 301 nuisent-elles vraiment au référencement ?
- □ La balise canonical bloque-t-elle vraiment l'indexation de vos pages ?
- □ Pourquoi Google voit-il majoritairement vos prix en dollars américains ?
- □ Hreflang et canonical : pourquoi Google les traite-t-il comme deux concepts distincts ?
- □ L'outil de désaveu supprime-t-il vraiment les backlinks toxiques de Google ?
- □ Comment différencier des pages produits identiques sans tomber dans le duplicate content ?
- □ Faut-il vraiment vérifier séparément chaque sous-domaine dans Search Console ?
- □ Faut-il vraiment s'inquiéter d'un volume important de 404 sur son site ?
- □ Faut-il vraiment marquer tous les liens d'affiliation avec rel=nofollow ou rel=sponsored ?
- □ Les quality raters impactent-ils vraiment le classement de votre site ?
- □ Combien de temps Google mémorise-t-il les anciennes URL après une migration ?
- □ L'indexation mobile-first est-elle vraiment généralisée à tous les sites ?
- □ Le domaine .ai est-il vraiment traité comme un gTLD par Google ?
- □ Faut-il vraiment réduire le nombre de pages indexées pour améliorer son SEO ?
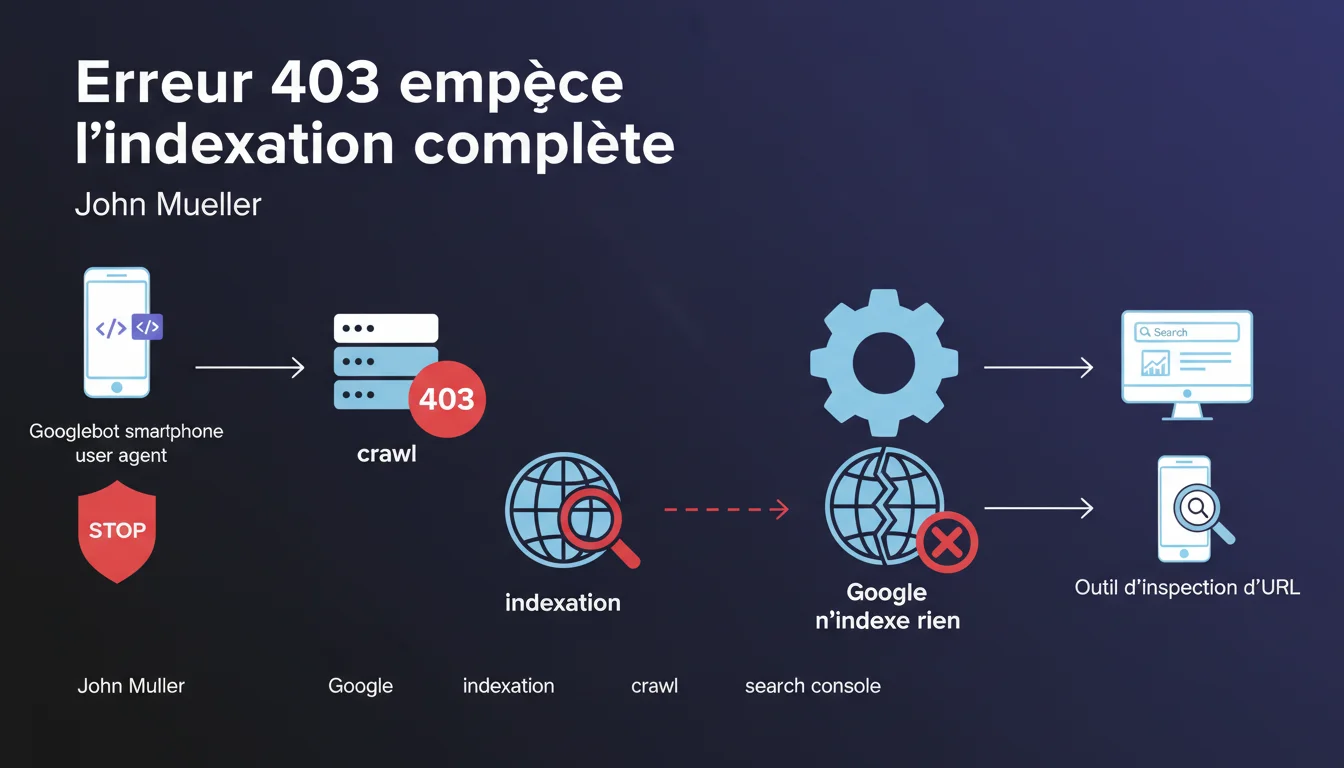
Si Googlebot crawle votre site avec un user agent smartphone et reçoit un code HTTP 403, Google considère qu'il n'y a rien à indexer et stoppe l'indexation. Cette situation peut paralyser la visibilité mobile de votre site. L'outil d'inspection d'URL dans Search Console permet de diagnostiquer ce problème critique.
Ce qu'il faut comprendre
Pourquoi Google traite-t-il le 403 comme un signal d'absence de contenu ?
Un code HTTP 403 signifie « accès interdit » — le serveur refuse explicitement de livrer la ressource demandée. Contrairement à un 404 (ressource introuvable) ou un 503 (indisponibilité temporaire), le 403 est perçu par Google comme une décision délibérée du site d'empêcher l'accès.
Quand Googlebot mobile rencontre un 403, il n'a aucun moyen de vérifier s'il s'agit d'une erreur de configuration ou d'une volonté réelle de bloquer les robots. Par sécurité, il considère qu'il n'y a rien à indexer et abandonne.
Cette règle s'applique-t-elle uniquement au crawl mobile ?
La déclaration de Mueller mentionne explicitement le user agent smartphone, ce qui fait sens avec l'indexation mobile-first généralisée depuis plusieurs années. Si votre site renvoie un 403 au Googlebot mobile, vous êtes dans l'impasse.
En revanche, un 403 renvoyé uniquement au Googlebot desktop pourrait ne pas bloquer totalement l'indexation si le crawl mobile fonctionne. Mais cette configuration est rarissime — la plupart des blocages 403 touchent tous les user agents ou sont mal configurés.
Comment diagnostiquer efficacement un problème de 403 ?
L'outil d'inspection d'URL dans Search Console simule le crawl de Googlebot et révèle immédiatement un code 403. Vous voyez le code HTTP retourné, l'user agent utilisé, et le contenu (ou l'absence de contenu) récupéré.
C'est le moyen le plus fiable de confirmer qu'un 403 bloque l'indexation. Les logs serveur et les tests manuels avec curl peuvent compléter, mais Search Console reste la référence.
- Un code 403 sur mobile = aucune indexation par Google
- Le 403 est interprété comme un refus délibéré d'accès, pas une erreur temporaire
- L'outil d'inspection d'URL dans Search Console est le diagnostic de référence
- Le problème touche principalement le Googlebot mobile, user agent prioritaire
- Contrairement au 503 (temporaire) ou au 404 (page inexistante), le 403 signale une interdiction permanente
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, et c'est même une réalité brutale que beaucoup découvrent trop tard. Les erreurs de configuration sur les règles de sécurité, les pare-feu applicatifs (WAF), ou les plugins de sécurité WordPress génèrent régulièrement des 403 pour Googlebot mobile sans que le propriétaire du site ne s'en rende compte.
Le piège classique : un site accessible depuis un navigateur standard, mais bloqué pour Googlebot à cause d'une règle anti-bot trop agressive. Résultat : désindexation progressive et chute de trafic organique inexpliquée. Les logs serveur révèlent souvent des milliers de 403 sur des URLs critiques.
Quelles nuances faut-il apporter à cette règle absolue ?
Mueller affirme « il n'y a rien à indexer, donc Google n'indexe rien » — c'est sans appel. Mais attention : si le 403 est intermittent (par exemple, un WAF mal calibré qui bloque aléatoirement), Google peut alterner entre succès et échec de crawl. Dans ce cas, l'indexation reste possible mais erratique et dégradée.
Autre nuance : si seule une partie du site (CSS, JS, images) renvoie des 403, Google peut encore indexer le HTML principal, mais le rendu sera cassé ou incomplet. Le contenu textuel peut apparaître dans l'index, mais sans mise en page ni interactivité — ce qui nuit au classement. [A vérifier] : Google pourrait-il tolérer des 403 sur des ressources secondaires sans impact majeur ? Les observations montrent que non, surtout si le rendu en dépend.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vous renvoyez un 403 volontairement sur des sections privées (espace membre, admin, contenu payant), c'est le comportement attendu et Google ne tentera pas de les indexer. Aucun problème ici.
Le drame survient quand le 403 touche des pages publiques et stratégiques par erreur. C'est là que l'indexation s'effondre. Donc cette règle s'applique toujours — mais elle n'est problématique que si le 403 est involontaire.
Impact pratique et recommandations
Que faut-il faire concrètement si Googlebot reçoit un 403 ?
Première étape : confirmer le problème avec l'outil d'inspection d'URL dans Search Console. Testez plusieurs URLs stratégiques (homepage, catégories, produits) pour voir si le 403 est généralisé ou localisé.
Ensuite, analysez les logs serveur pour identifier la cause : règle WAF, plugin de sécurité, restriction IP, fichier .htaccess mal configuré. La plupart des 403 involontaires proviennent de solutions de sécurité trop agressives qui confondent Googlebot avec un bot malveillant.
Quelles erreurs éviter absolument ?
Ne jamais bloquer Googlebot via robots.txt et renvoyer un 403 — c'est un double verrouillage qui paralyse l'indexation. Si vous voulez empêcher l'accès à une section, choisissez : soit robots.txt (Google ne crawle pas mais peut indexer l'URL), soit 403 (Google ne peut même pas tenter le crawl).
Autre erreur fréquente : corriger le 403 sans demander une réindexation via Search Console. Google peut mettre des semaines à re-crawler naturellement les URLs affectées. Accélérez le processus en soumettant manuellement les pages critiques.
Comment vérifier que mon site est conforme et protégé contre les 403 involontaires ?
Mettez en place une surveillance automatisée des codes HTTP retournés pour Googlebot. Des outils comme Oncrawl, Screaming Frog (en mode crawl programmé), ou des scripts personnalisés peuvent alerter en temps réel sur l'apparition de 403.
Testez régulièrement votre site avec des user agents simulant Googlebot mobile. Un simple script curl ou un outil comme Httpstatus.io suffit pour valider l'accessibilité.
- Utiliser l'outil d'inspection d'URL pour confirmer le code HTTP reçu par Googlebot
- Examiner les logs serveur pour identifier la source du 403 (WAF, plugin, règle serveur)
- Vérifier les règles de sécurité Cloudflare, Sucuri, mod_security et whitelister Googlebot si nécessaire
- Ne jamais combiner robots.txt disallow et code 403 sur les mêmes URLs
- Soumettre les URLs corrigées via Search Console pour accélérer la réindexation
- Mettre en place une surveillance automatisée des codes HTTP pour détecter les régressions
- Tester régulièrement avec un user agent Googlebot mobile pour valider l'accessibilité
❓ Questions frequentes
Un 403 temporaire peut-il causer une désindexation permanente ?
Dois-je m'inquiéter si seules les ressources CSS/JS reçoivent un 403 ?
Comment différencier un 403 légitime (zone privée) d'un 403 involontaire ?
Un 403 côté serveur est-il pire qu'un 403 côté WAF ou CDN ?
Combien de temps faut-il pour retrouver l'indexation après correction d'un 403 ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 11/07/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.