Declaration officielle
Ce qu'il faut comprendre
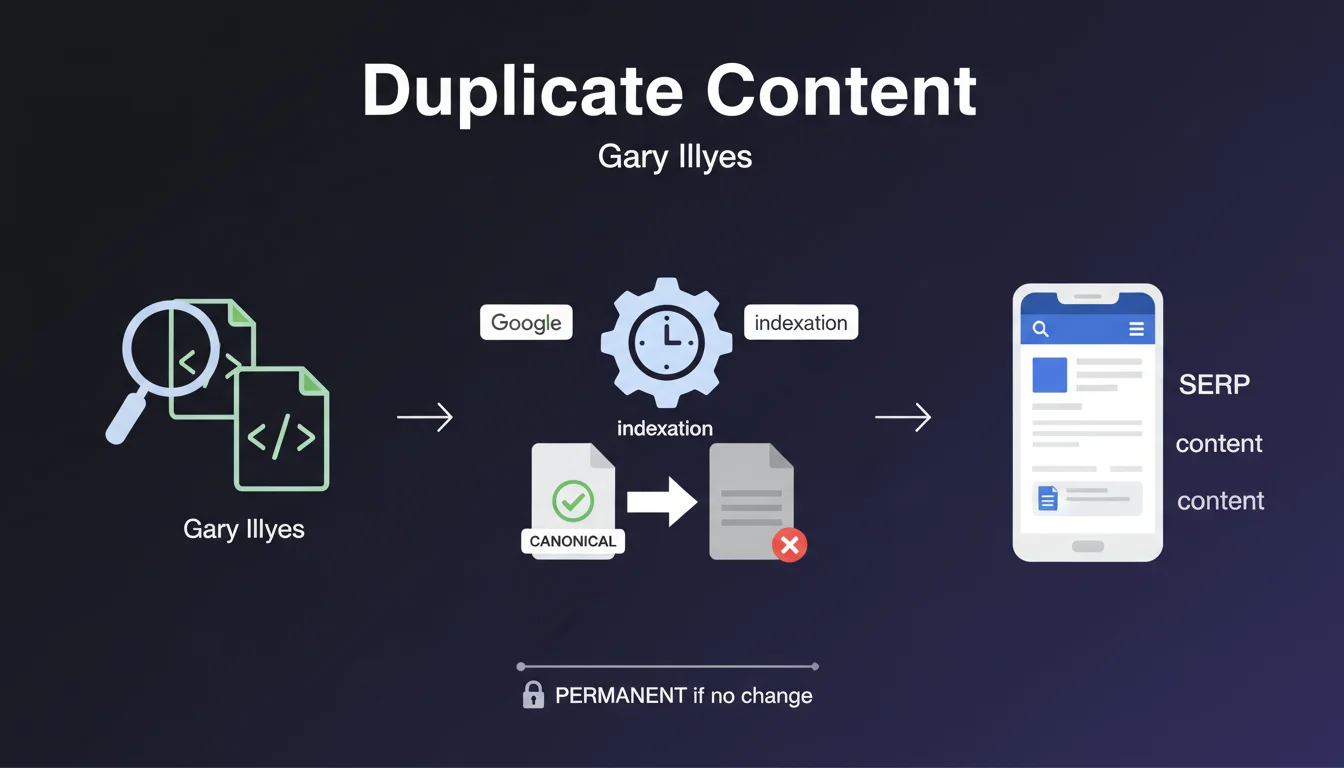
Cette déclaration de Paul Haahr, ingénieur senior chez Google, apporte un éclairage précieux sur la stabilité des algorithmes de détection du contenu dupliqué. Contrairement à ce que beaucoup pensent, ces mécanismes n'ont pas connu de révolution majeure depuis plusieurs années.
Cela signifie que Google a trouvé un équilibre relativement stable dans sa façon d'identifier et de traiter le duplicate content. Les améliorations sont incrémentales, progressives, mais l'architecture fondamentale reste la même.
Pour les praticiens SEO, cette information est rassurante : les bonnes pratiques établies en matière de gestion du contenu dupliqué restent pertinentes. Il n'y a pas de changement de paradigme brutal à anticiper.
- Les algorithmes évoluent constamment mais sans changement radical de conception
- La stabilité structurelle permet une approche prévisible du duplicate content
- Les fondamentaux SEO en matière de contenu unique restent valables
- Google affine en continu sa capacité à détecter les variations subtiles de duplication
Avis d'un expert SEO
Cette déclaration correspond effectivement à ce que nous observons sur le terrain. Les pénalités liées au duplicate content n'ont pas fondamentalement changé de nature depuis des années, même si Google devient plus subtil dans sa détection.
Cependant, il faut nuancer : si l'algorithme de base reste stable, Google a considérablement amélioré sa compréhension sémantique du contenu. Deux textes qui ne sont pas identiques mot pour mot mais qui véhiculent la même information peuvent désormais être traités comme du near-duplicate content.
Dans les secteurs e-commerce notamment, nous constatons que Google privilégie de plus en plus les descriptions produits originales et sait identifier les contenus génériques recopiés entre sites.
Impact pratique et recommandations
- Auditez régulièrement votre site pour identifier les contenus dupliqués internes (URLs avec paramètres, versions imprimables, pagination)
- Implémentez correctement les balises canonical pour indiquer à Google quelle version d'un contenu est prioritaire
- Utilisez le fichier robots.txt et les meta robots pour empêcher l'indexation des pages dupliquées nécessaires (filtres, tris)
- Créez du contenu unique et original plutôt que de reprendre des descriptions fournisseurs ou des textes génériques
- Surveillez les scraping externes de votre contenu et utilisez les outils Google pour signaler les copies malveillantes
- Pour les sites multilingues, utilisez correctement les balises hreflang pour éviter les problèmes de duplication internationale
- Évitez le content spinning et les variations artificielles : Google les détecte de mieux en mieux
- Privilégiez la consolidation de contenus similaires plutôt que leur multiplication sur différentes URLs
La gestion stratégique du duplicate content nécessite une approche technique pointue couplée à une vision éditoriale cohérente. Entre l'audit de milliers d'URLs, la mise en place correcte des directives techniques et la création de contenus véritablement différenciants, le chantier peut s'avérer complexe.
Pour les sites de moyenne à grande envergure, particulièrement dans l'e-commerce ou les secteurs avec de nombreuses pages similaires, l'accompagnement par une agence SEO spécialisée permet d'établir une stratégie sur-mesure, d'automatiser les bonnes pratiques et de prioriser les actions selon leur impact réel sur votre visibilité.
💬 Commentaires (0)
Soyez le premier à commenter.