Declaration officielle
Ce qu'il faut comprendre
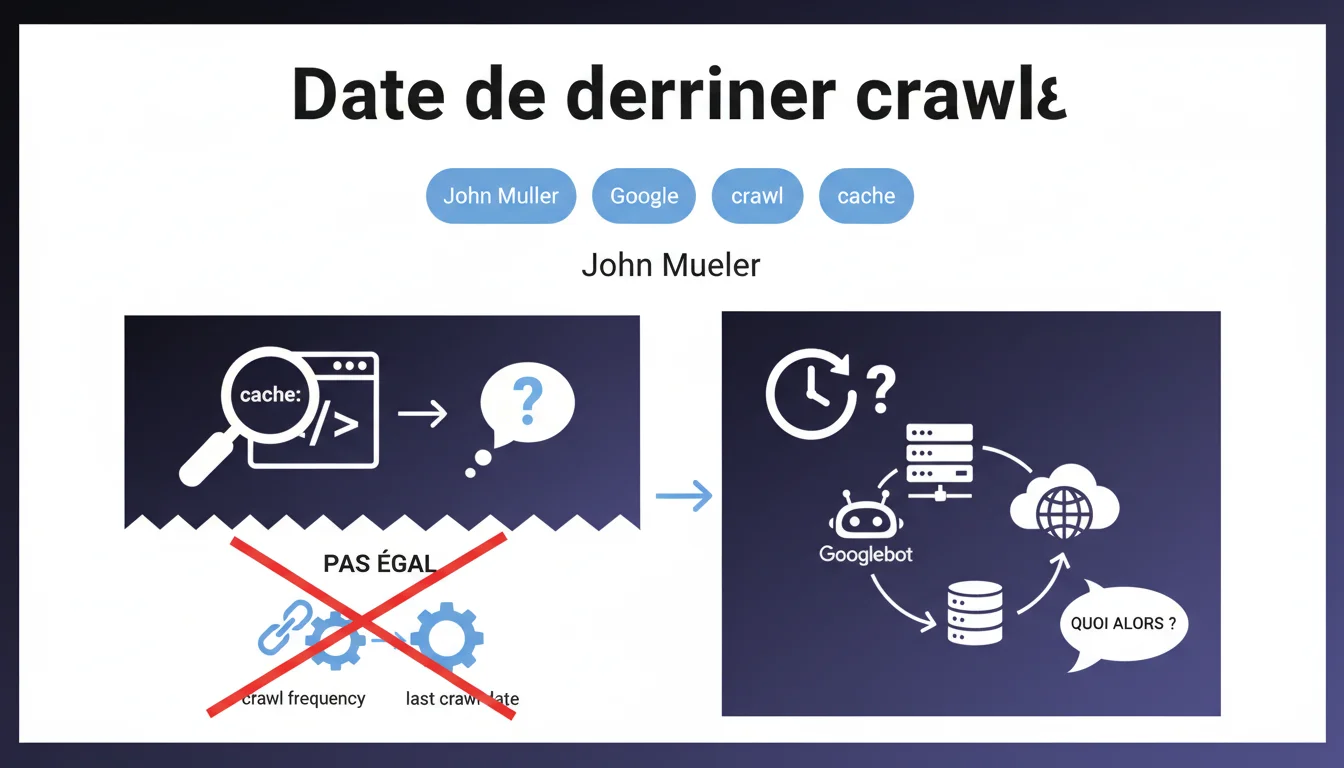
Que représente vraiment la date affichée dans le cache Google ?
Lorsqu'un praticien SEO utilise la commande cache: pour consulter la version en cache d'une page, Google affiche une date en haut de la page. Cette information a longtemps été considérée comme un indicateur de la dernière visite de Googlebot sur la page.
Selon la déclaration de John Mueller, cette date n'est pas nécessairement représentative du dernier crawl réel. Elle pourrait correspondre à d'autres événements techniques dans le processus d'indexation de Google, sans refléter fidèlement l'activité du crawler.
Pourquoi cette précision change-t-elle notre compréhension du crawl ?
Cette clarification bouleverse une pratique courante en SEO : utiliser la date du cache comme métrique de fraîcheur du crawl. De nombreux professionnels s'appuyaient sur cet indicateur pour évaluer la santé de leur crawl budget.
Google maintient en réalité plusieurs versions d'une même page dans son infrastructure. La date affichée peut correspondre à une version spécifique mise en cache pour l'affichage aux utilisateurs, mais pas forcément à la dernière analyse complète de la page.
- La date du cache n'est pas un indicateur fiable de la fréquence de crawl réelle
- Google peut crawler une page sans mettre à jour la version en cache visible
- Plusieurs versions d'une page peuvent coexister dans l'infrastructure Google
- Cette date peut refléter d'autres événements techniques que le crawl
Quelles sont les alternatives pour mesurer le crawl efficacement ?
Face à cette limitation, les praticiens SEO doivent se tourner vers des sources d'information plus fiables. La Search Console reste l'outil le plus précis pour analyser l'activité de crawl.
Les logs serveur constituent également une source primaire incontournable pour observer directement les passages de Googlebot, avec des timestamps précis et des informations sur les ressources consultées.
Avis d'un expert SEO
Cette révélation est-elle cohérente avec les observations terrain ?
En tant qu'expert SEO, cette déclaration confirme ce que beaucoup d'entre nous observaient déjà : des incohérences flagrantes entre la date du cache et les données de crawl dans la Search Console ou les logs serveur.
Il n'est pas rare de constater qu'une page affiche une date de cache ancienne alors que les logs montrent des passages quotidiens de Googlebot. Inversement, certaines pages avec une date de cache récente ne montrent aucune activité significative dans les statistiques d'exploration.
Quelles implications pour l'analyse de l'indexation ?
Cette clarification met en lumière la complexité du système d'indexation de Google. Le moteur de recherche ne fonctionne pas de manière linéaire : crawl, indexation et mise en cache sont des processus distincts et asynchrones.
Un contenu peut être crawlé, analysé et pris en compte dans le classement sans que le cache public soit actualisé. Cette dissociation explique pourquoi des modifications de contenu peuvent impacter le positionnement avant même que la date du cache ne change.
Dans quels cas cette information peut-elle encore servir ?
Malgré ses limites, la date du cache conserve une certaine utilité pour détecter des problèmes majeurs d'indexation. Si aucune version en cache n'existe ou si la date remonte à plusieurs mois sur un site actif, c'est généralement le signe d'un dysfonctionnement.
Elle peut également servir d'indicateur complémentaire dans une analyse plus large, mais jamais comme métrique unique ou principale pour évaluer la santé du crawl d'un site.
Impact pratique et recommandations
Comment mesurer efficacement la fréquence de crawl maintenant ?
La première action concrète consiste à privilégier la Search Console comme source d'information principale. Le rapport "Statistiques d'exploration" fournit des données précises sur le nombre de requêtes, les pages explorées et les erreurs rencontrées.
L'analyse des fichiers logs serveur doit devenir un réflexe pour tout site professionnel. Cette méthode offre une vision exhaustive et non filtrée de l'activité réelle de Googlebot, avec tous les détails techniques nécessaires.
- Configurer un accès régulier au rapport "Statistiques d'exploration" de la Search Console
- Mettre en place une solution d'analyse des logs serveur (Oncrawl, Botify, ou scripts personnalisés)
- Croiser les données de plusieurs sources pour obtenir une vision complète
- Cesser d'utiliser la date du cache comme métrique de performance du crawl
- Documenter les patterns de crawl observés pour identifier les anomalies rapidement
Quelles erreurs d'interprétation faut-il éviter absolument ?
L'erreur la plus courante serait de continuer à baser des décisions stratégiques sur la date du cache. Ne paniquez pas si cette date semble ancienne alors que vos autres indicateurs sont au vert.
Évitez également de surinterpréter les variations de cette date. Une mise à jour du cache ne signifie pas nécessairement une amélioration du crawl, et inversement. Concentrez-vous sur les métriques fiables et actionnables.
Quelle stratégie adopter pour optimiser le crawl de mon site ?
Au-delà de la mesure, l'objectif reste d'optimiser la crawlabilité technique de votre site. Travaillez sur la structure des liens internes, la vitesse de réponse du serveur, et la qualité du fichier robots.txt et du sitemap XML.
Investissez dans une architecture d'information claire qui facilite la découverte de vos contenus importants. Le maillage interne reste l'un des leviers les plus puissants pour guider Googlebot vers vos pages stratégiques.
💬 Commentaires (0)
Soyez le premier à commenter.