Declaration officielle
Ce qu'il faut comprendre
Que nous apprend cette vidéo sur le fonctionnement de Googlebot ?
Google a relancé sa série de vidéos éducatives SEO, après l'ère Matt Cutts, pour expliquer les fondamentaux du référencement. Cette première vidéo se concentre sur le processus de crawl, c'est-à-dire la manière dont Googlebot découvre et parcourt les pages d'un site web.
L'objectif affiché est de vulgariser les concepts de base pour les débutants et les gestionnaires de sites web qui n'ont pas nécessairement de connaissances SEO avancées. Il s'agit d'un retour aux sources, avec un format court et accessible.
Pourquoi Google publie-t-il des contenus aussi basiques ?
La stratégie de Google vise à démocratiser le SEO et à réduire les mythes qui circulent dans l'industrie. En expliquant directement les principes fondamentaux, Google espère améliorer la qualité globale du web et faciliter le travail de son moteur de recherche.
Ces vidéos servent également de référence officielle pour contrer les pratiques douteuses ou les mauvais conseils qui circulent. Elles établissent une source d'information fiable et accessible à tous.
Quels sont les concepts essentiels abordés dans cette vidéo ?
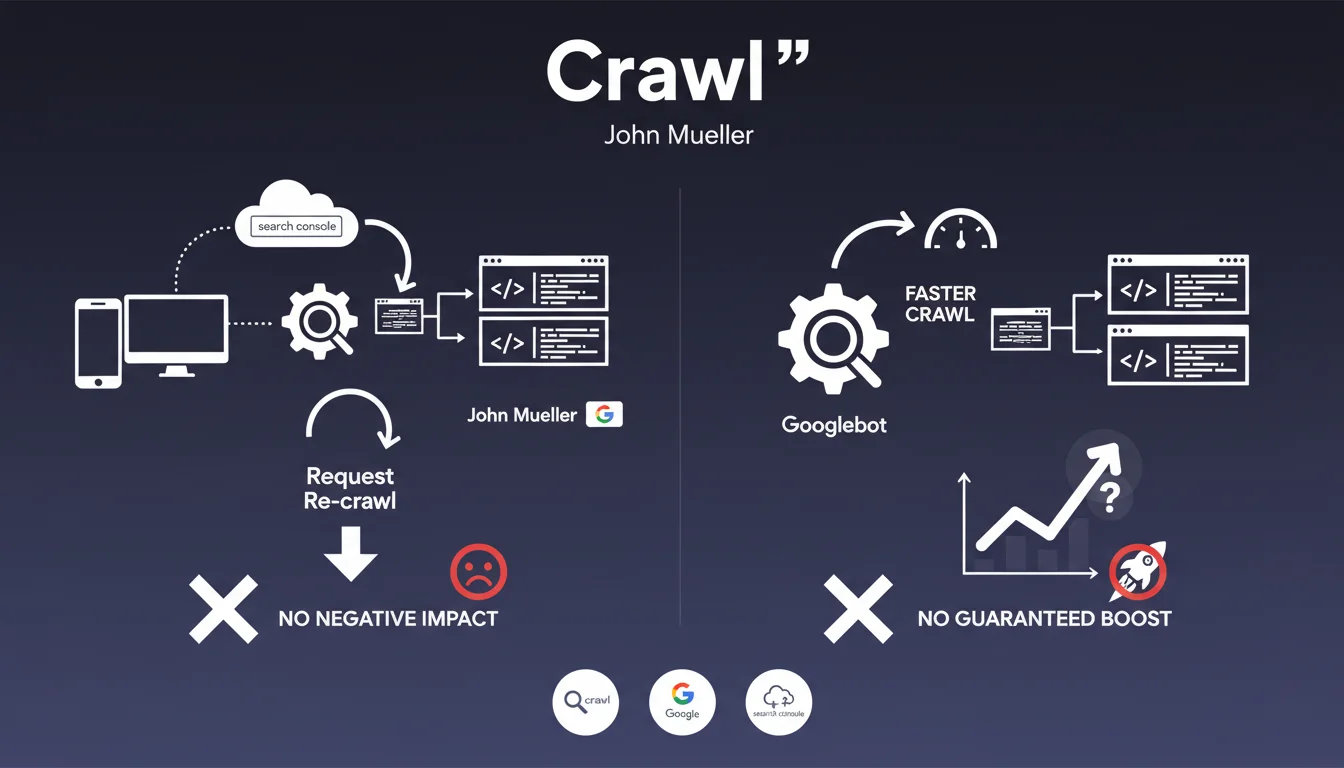
Bien que très basique, la vidéo rappelle que Googlebot suit les liens internes et externes pour découvrir de nouvelles pages. Elle explique le concept de budget de crawl et la priorisation que fait Google des pages à explorer.
- Le crawl démarre par des URLs connues (sitemap, pages déjà indexées, liens externes)
- Googlebot suit les liens hypertextes pour découvrir de nouvelles pages
- Le budget de crawl limite le nombre de pages explorées par visite
- La fréquence de crawl dépend de la popularité et de la fréquence de mise à jour du site
- Les fichiers robots.txt permettent de contrôler l'accès de Googlebot
Avis d'un expert SEO
Cette approche pédagogique est-elle vraiment utile pour les professionnels SEO ?
Pour un praticien SEO expérimenté, cette vidéo n'apporte effectivement aucune information nouvelle. Les concepts présentés sont connus depuis des années et font partie du B.A.BA de notre métier quotidien.
Cependant, l'intérêt réside ailleurs : ces vidéos constituent une base documentaire officielle que nous pouvons utiliser pour former nos clients ou nos équipes. Elles permettent également de valider que nos connaissances fondamentales sont toujours d'actualité et conformes à la vision de Google.
Quels aspects importants du crawl ne sont pas abordés dans cette vidéo ?
La vidéo reste en surface et n'aborde pas les subtilités techniques qui font la différence en SEO professionnel. Par exemple, elle ne mentionne pas le concept de crawl différencié selon le type de Googlebot (desktop, mobile, image, etc.).
Elle omet également les aspects liés à la priorisation algorithmique du crawl basée sur le PageRank interne, la fraîcheur du contenu, ou encore l'impact des signaux de qualité sur la fréquence de visite de Googlebot.
Dans quels contextes ces informations basiques sont-elles insuffisantes ?
Pour les sites e-commerce avec des milliers de pages produits, les sites d'actualités avec du contenu très fréquent, ou les sites multilingues complexes, cette approche simplifiée ne suffit absolument pas. Ces environnements nécessitent une gestion fine du crawl budget.
De même, pour les sites confrontés à des problèmes de crawl (pages orphelines, crawl trap, duplication), cette vidéo n'apporte aucune solution concrète. Il faut alors mettre en place des stratégies avancées d'architecture et de maillage interne.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl de son site ?
Même si la vidéo reste basique, elle rappelle l'importance de faciliter le travail de Googlebot. Concrètement, cela signifie créer une architecture claire avec un maillage interne cohérent et des sitemaps XML à jour.
Il est essentiel de monitorer régulièrement la façon dont Googlebot explore votre site via la Google Search Console, en particulier les statistiques de crawl et les erreurs rencontrées. Cela vous permet d'identifier rapidement les problèmes.
Quelles erreurs courantes faut-il absolument éviter ?
L'erreur la plus fréquente est de bloquer involontairement des ressources importantes (CSS, JavaScript) via le robots.txt, ce qui empêche Google de comprendre correctement vos pages. Vérifiez régulièrement votre fichier robots.txt.
Autre erreur : négliger le temps de réponse serveur. Si votre site est lent, Googlebot réduit automatiquement son crawl pour ne pas surcharger vos serveurs, ce qui ralentit l'indexation de vos nouvelles pages.
- Créer et soumettre un sitemap XML complet et à jour via la Search Console
- Optimiser la structure de liens internes pour que toutes les pages importantes soient accessibles en 3 clics maximum
- Surveiller les statistiques de crawl dans la Google Search Console mensuellement
- Corriger rapidement les erreurs 404 et redirections détectées par Googlebot
- Améliorer le temps de réponse serveur (idéalement sous 200ms)
- Utiliser le robots.txt de manière stratégique pour éviter le gaspillage de crawl budget
- Analyser les logs serveur pour identifier les pages sur-crawlées ou sous-crawlées
- Implémenter des liens canoniques pour éviter le crawl de contenu dupliqué
Comment vérifier que votre site est correctement crawlé par Google ?
La Google Search Console reste votre meilleur allié. Consultez régulièrement la section "Statistiques d'exploration" pour analyser les tendances de crawl, le nombre de requêtes, et les temps de réponse.
Complétez cette analyse par l'examen des logs serveur qui vous donnent une vision exhaustive du comportement réel de Googlebot sur votre infrastructure. Cela permet d'identifier les anomalies que la Search Console ne révèle pas toujours.
💬 Commentaires (0)
Soyez le premier à commenter.