Declaration officielle
Ce qu'il faut comprendre
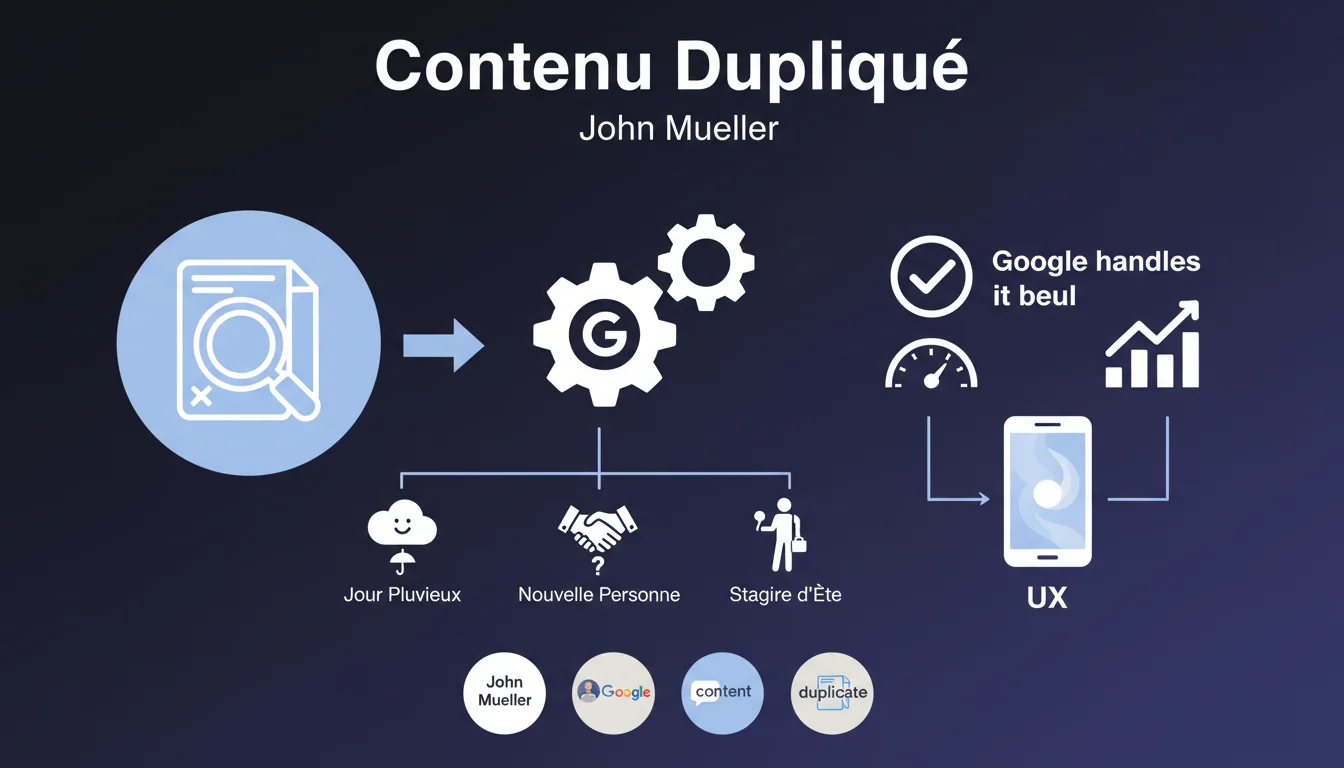
Que dit exactement Google sur le duplicate content ?
Google affirme via John Mueller que le contenu dupliqué est une problématique mineure, à traiter uniquement lorsque les équipes n'ont rien de plus important à faire. Selon lui, les algorithmes de Google sont suffisamment sophistiqués pour gérer cette situation sans intervention humaine.
Cette position officielle suggère que les webmasters ne devraient pas investir trop de temps ou de ressources à résoudre les problèmes de duplicate content. Google prétend filtrer et sélectionner automatiquement la version la plus pertinente d'un contenu.
Pourquoi Google minimise-t-il l'importance du contenu dupliqué ?
Google souhaite rassurer les webmasters sur le fait que le duplicate content ne déclenche pas de pénalité directe. L'objectif est d'éviter que les propriétaires de sites ne paniquent pour des duplications techniques mineures ou involontaires.
Le moteur de recherche dispose effectivement de mécanismes pour détecter et consolider les contenus identiques, en choisissant une URL canonique à afficher dans les résultats.
Quels sont les points essentiels de cette déclaration ?
- Le contenu dupliqué n'entraîne pas de pénalité algorithmique directe selon Google
- Les algorithmes sont censés sélectionner automatiquement la meilleure version d'un contenu
- Google considère cette problématique comme secondaire dans une stratégie SEO
- La gestion du duplicate content devrait être une tâche de faible priorité selon cette vision officielle
Avis d'un expert SEO
Cette déclaration correspond-elle à la réalité observée sur le terrain ?
L'expérience des praticiens SEO contredit largement cette affirmation optimiste. Dans la pratique, le contenu dupliqué génère régulièrement des problèmes de cannibalisation, de dilution du PageRank et de mauvais choix d'URL par Google.
Les sites qui laissent Google gérer seul leur duplicate content constatent fréquemment que le moteur indexe la mauvaise version d'une page, ou pire, dilue l'autorité entre plusieurs URLs identiques. Les résultats en termes de positionnement sont souvent sous-optimaux.
Quelles nuances importantes faut-il apporter à cette position ?
Il existe une différence majeure entre le duplicate content involontaire (versions imprimables, paramètres d'URL) et le contenu copié massivement. Google tolère le premier mais peut effectivement sanctionner le second.
La réalité est que même sans pénalité, le duplicate content provoque une perte d'efficacité SEO. Vos pages se font concurrence, votre crawl budget est gaspillé, et Google doit deviner quelle version privilégier plutôt que de recevoir des signaux clairs.
Dans quels cas cette minimisation du problème devient-elle dangereuse ?
Pour les sites de grande envergure (e-commerce, portails, annuaires), ignorer le duplicate content est une erreur stratégique majeure. Ces sites génèrent naturellement des milliers de variations d'URLs et de contenus similaires.
Les sites utilisant des systèmes de pagination, de filtres ou de tri créent également du contenu dupliqué massif. Sans gestion proactive via canonicals, noindex ou paramètres Search Console, ces sites perdent en efficacité et en visibilité organique.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer le duplicate content ?
Ne laissez jamais Google décider seul quelle version de votre contenu indexer. Utilisez systématiquement les balises canonical pour indiquer clairement votre URL préférentielle sur toutes les variations.
Implémentez une stratégie de gestion proactive : redirections 301 pour les contenus définitivement dupliqués, balises noindex pour les pages utiles mais non stratégiques, et paramètres d'URL dans la Search Console pour les variations dynamiques.
Pour les sites multilingues ou multi-régionaux, utilisez les balises hreflang pour éviter que Google ne considère vos versions linguistiques comme du duplicate content. Cette configuration technique est cruciale mais souvent négligée.
Quelles erreurs critiques doit-on absolument éviter ?
- Ne jamais bloquer les pages dupliquées dans le robots.txt (Google ne peut alors pas voir les canonicals)
- Ne pas laisser plusieurs versions d'une même page sans signal canonique clair
- Ne pas ignorer le duplicate content sur les sites à forte volumétrie ou e-commerce
- Ne pas se fier uniquement aux algorithmes de Google pour choisir la bonne URL
- Ne pas négliger l'impact du duplicate content sur le crawl budget pour les gros sites
Comment auditer et corriger efficacement son site ?
Utilisez des outils comme Screaming Frog, OnCrawl ou Sitebulb pour identifier toutes les duplications. Analysez les URLs indexées dans la Search Console pour repérer les versions non canoniques présentes dans l'index.
Créez une matrice de priorisation : traitez d'abord le duplicate content sur vos pages stratégiques à fort trafic, puis étendez progressivement aux pages secondaires. Mesurez l'impact de chaque correction sur vos positions et votre trafic organique.
💬 Commentaires (0)
Soyez le premier à commenter.