Declaration officielle
Ce qu'il faut comprendre
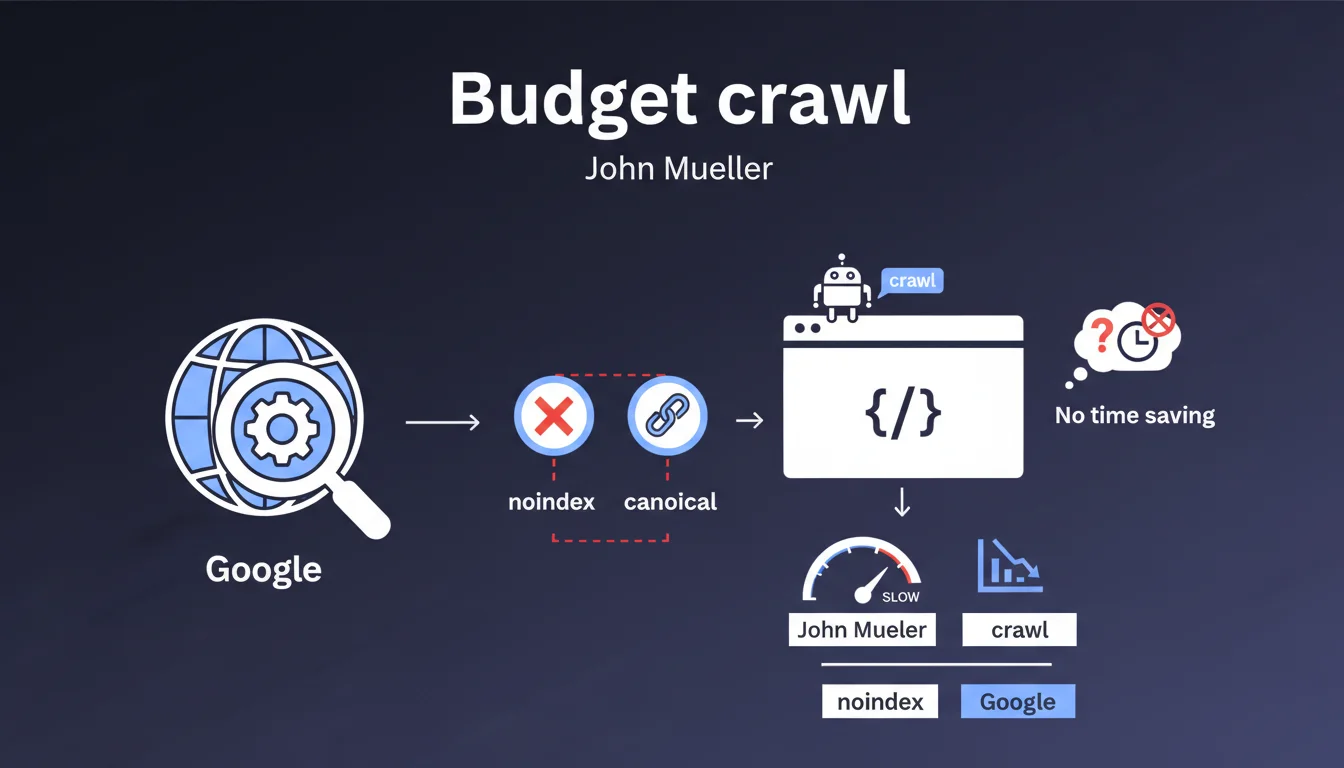
Pourquoi la balise noindex ne peut-elle pas économiser du budget crawl ?
Pour comprendre cette affirmation de John Mueller, il faut revenir au fonctionnement de Googlebot. Lorsque le robot explore une page, il doit d'abord charger le code HTML pour en analyser le contenu.
La balise meta robots noindex se trouve justement dans l'en-tête HTML de la page. Googlebot doit donc obligatoirement crawler la page pour découvrir cette directive. Le budget crawl a déjà été consommé au moment où le robot lit l'instruction lui demandant de ne pas indexer le contenu.
Qu'en est-il des balises canonical dans cette logique ?
Le même principe s'applique aux balises canonical. Pour identifier qu'une page est une version alternative pointant vers une URL canonique, Googlebot doit crawler la page et lire son code source.
La consommation de ressources serveur et de temps de crawl reste identique, que la page contienne ou non ces directives. Seul le traitement post-crawl diffère : indexation ou non, consolidation des signaux vers l'URL canonique.
Quelles sont les véritables méthodes pour économiser du budget crawl ?
Si votre objectif est réellement d'optimiser le budget crawl, vous devez empêcher Googlebot d'accéder aux pages en amont, avant même le chargement du HTML.
- Fichier robots.txt : bloquer les URLs ou répertoires entiers empêche le crawl effectif
- Codes HTTP 404 ou 410 : signalent que la ressource n'existe plus, Googlebot cesse rapidement de les crawler
- Suppression physique des pages : éliminer les contenus inutiles réduit la surface à explorer
- Optimisation de l'architecture : limiter la profondeur de crawl et les chaînes de redirections
- Fichier sitemap XML ciblé : guider Googlebot vers les pages importantes uniquement
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain des SEO ?
Absolument. Les logs serveur confirment systématiquement que Googlebot continue de crawler régulièrement les pages marquées noindex. On observe même parfois une fréquence de crawl importante sur ces URLs, car Google doit vérifier périodiquement si la directive a été modifiée.
Cette réalité technique est souvent mal comprise par les débutants en SEO qui pensent que noindex = page ignorée. En réalité, noindex signifie crawlée mais non indexée. La nuance est fondamentale pour l'optimisation du budget crawl.
Dans quels cas cette règle pourrait-elle créer de la confusion ?
La confusion vient souvent de la combinaison robots.txt + noindex. Si vous bloquez une page en robots.txt, Googlebot ne peut pas accéder au HTML et donc ne voit jamais la balise noindex. Résultat : la page peut rester indexée avec un snippet "Aucune information disponible".
Autre cas problématique : les sites avec des milliers de pages paginées ou de facettes marquées noindex. Ces pages consomment du budget crawl sans apporter de valeur, créant un goulot d'étranglement pour les contenus réellement stratégiques.
Quelles sont les implications pour les sites à forte volumétrie ?
Pour les sites de plusieurs centaines de milliers de pages, cette réalité technique devient critique. Chaque page crawlée mobilise des ressources serveur et du temps Googlebot, même si elle est en noindex.
Les plateformes e-commerce, les sites d'annonces ou les portails d'actualités doivent être particulièrement vigilants. Une mauvaise gestion des paramètres d'URL, des filtres et des paginations peut conduire à un crawl massif de pages à faible valeur, ralentissant la découverte et l'indexation des nouveaux contenus stratégiques.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser son budget crawl ?
La première étape consiste à auditer votre crawl actuel via les logs serveur et la Search Console. Identifiez les pages qui consomment du budget sans créer de valeur : pages noindex, redirections, erreurs 404 fréquemment crawlées.
Ensuite, établissez une stratégie claire : les pages inutiles doivent être bloquées en robots.txt ou supprimées physiquement. Réservez le noindex aux pages qui doivent rester accessibles aux utilisateurs mais pas aux moteurs de recherche (résultats de recherche interne, pages de compte utilisateur, etc.).
Pour les contenus dupliqués, privilégiez systématiquement la canonical plutôt que le noindex si vous souhaitez consolider les signaux. Mais soyez conscient que toutes les versions seront quand même crawlées.
Quelles erreurs éviter absolument dans la gestion du budget crawl ?
- Ne jamais bloquer en robots.txt une page que vous souhaitez désindexer avec noindex
- Éviter d'accumuler des milliers de pages noindex sans réelle nécessité stratégique
- Ne pas utiliser noindex comme solution de facilité pour gérer du contenu de faible qualité
- Éviter les chaînes de redirections multiples qui multiplient les requêtes Googlebot
- Ne pas négliger l'optimisation du temps de réponse serveur qui impacte directement le crawl
- Éviter de générer automatiquement des millions de pages de faible valeur sans mécanisme de contrôle
Comment vérifier et monitorer l'efficacité de ses optimisations ?
Mettez en place un monitoring régulier via Google Search Console. Analysez le rapport de statistiques d'exploration pour suivre l'évolution du nombre de pages crawlées quotidiennement et le temps de téléchargement moyen.
L'analyse des fichiers logs reste la méthode la plus précise. Elle vous permet d'identifier exactement quelles sections de votre site monopolisent Googlebot et d'ajuster votre stratégie en conséquence.
Surveillez également le délai entre la publication de nouveaux contenus et leur indexation. Un délai qui s'allonge peut indiquer un problème de budget crawl saturé.
💬 Commentaires (0)
Soyez le premier à commenter.