Declaration officielle
Ce qu'il faut comprendre
Pourquoi cette déclaration de Google remet-elle en question certaines croyances SEO ?
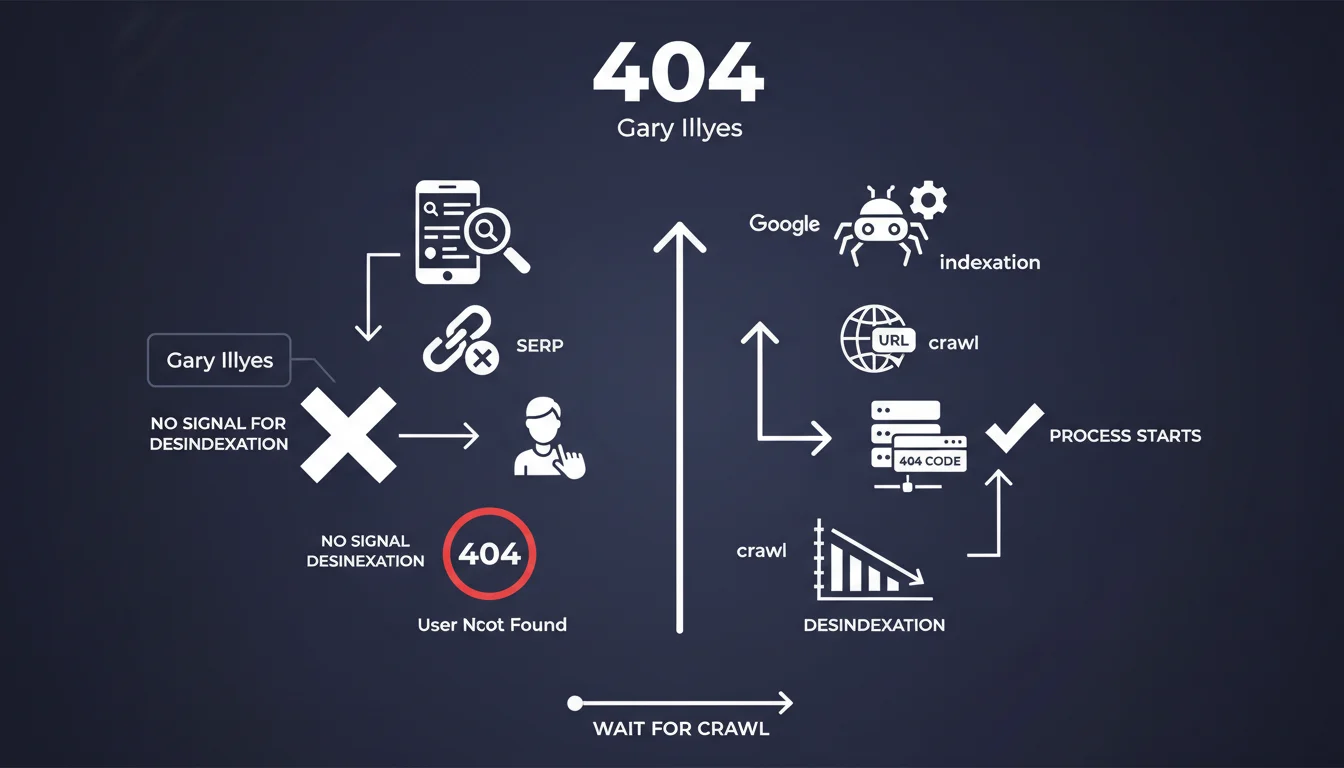
De nombreux praticiens SEO pensent que l'expérience utilisateur négative après le clic (bounce immédiat, retour rapide vers les SERP) envoie des signaux à Google. Cette déclaration officielle vient clarifier que Google ne se base pas sur le comportement post-clic pour décider de désindexer une URL.
La désindexation d'une page en 404 suit un processus technique strict : Googlebot doit crawler l'URL, constater le code d'erreur 404, puis enclencher la procédure de suppression. Le simple fait qu'un internaute arrive sur une page cassée depuis les résultats n'accélère pas ce processus.
Comment fonctionne réellement le processus de désindexation d'une page 404 ?
Le mécanisme est purement basé sur le crawl et les codes de statut HTTP. Googlebot doit d'abord revisiter l'URL concernée dans le cadre de son processus normal d'exploration.
Ce n'est qu'après avoir constaté techniquement le code HTTP 404 que Google initie la désindexation. Le délai dépend donc de la fréquence de crawl de votre site et de l'importance de l'URL dans votre architecture.
Qu'est-ce que cela nous apprend sur la connaissance de Google du comportement utilisateur ?
Google réaffirme officiellement qu'il ne trace pas l'expérience après le clic depuis les SERP. Les données d'interaction post-clic ne sont pas utilisées comme signaux de ranking ou de désindexation.
- Les clics depuis les SERP vers une page 404 ne déclenchent aucun signal de suppression
- Seul le crawl de Googlebot et la détection du code 404 activent la désindexation
- Le délai de désindexation dépend de la fréquence de crawl de l'URL concernée
- Google maintient qu'il ne suit pas le comportement utilisateur après la SERP
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
En 15 ans de pratique, j'observe effectivement que les pages 404 peuvent rester indexées pendant des semaines, même avec un trafic significatif depuis les SERP. La corrélation entre trafic utilisateur et vitesse de désindexation est inexistante.
Cette déclaration est parfaitement cohérente avec la réalité technique : les sites à crawl peu fréquent conservent leurs 404 en index beaucoup plus longtemps, indépendamment du volume de clics reçus. Les sites d'actualité avec crawl intensif voient leurs 404 disparaître en quelques heures.
Quelles nuances faut-il apporter à cette position officielle ?
Si Google affirme ne pas utiliser les données comportementales post-clic directement, cela ne signifie pas qu'elles n'existent pas dans leurs systèmes. Chrome, Android et Analytics collectent ces données, même si officiellement elles ne servent pas au ranking.
La nuance importante concerne les soft 404 : une page qui renvoie un code 200 mais affiche un contenu d'erreur. Dans ce cas, Google pourrait théoriquement utiliser des signaux comportementaux pour identifier le problème, même si le code HTTP est correct.
Dans quels cas cette règle pourrait-elle avoir des exceptions ?
Pour les sites avec crawl budget très limité, une page 404 rarement visitée par Googlebot pourrait rester indexée pendant des mois. Dans ces cas, forcer un recrawl via Search Console devient indispensable.
Les pages avec redirections 302 temporaires vers des 404 représentent aussi un cas particulier : Google peut conserver l'URL d'origine en index plus longtemps, attendant que la redirection devienne permanente ou que l'URL cible soit stable.
Impact pratique et recommandations
Que faut-il faire concrètement lorsqu'on supprime des pages ?
Ne comptez jamais sur le comportement utilisateur pour accélérer la désindexation. Utilisez systématiquement les outils à votre disposition pour forcer la prise en compte des suppressions.
La meilleure pratique consiste à soumettre les URL supprimées via Search Console dans l'outil de suppression d'URL. Cela accélère considérablement le processus plutôt que d'attendre le prochain crawl naturel.
- Vérifier que vos pages supprimées renvoient bien un code HTTP 404 (pas 200, ni 302)
- Utiliser l'outil de suppression d'URL dans Google Search Console pour accélérer la désindexation
- Mettre à jour votre sitemap XML en retirant les URL supprimées
- Corriger tous les liens internes pointant vers les 404 pour éviter le gaspillage de crawl budget
- Monitorer les soft 404 dans Search Console et les corriger en priorité
Quelles erreurs éviter absolument dans la gestion des 404 ?
L'erreur la plus fréquente est de créer des soft 404 : pages qui affichent un message d'erreur mais renvoient un code 200. Google les gardera indexées indéfiniment car techniquement elles semblent fonctionnelles.
Autre piège : utiliser des redirections 302 temporaires vers la page d'accueil pour masquer les 404. Google conserve l'URL d'origine en index et considère la situation comme temporaire, retardant la désindexation.
Comment optimiser la gestion des erreurs 404 à l'échelle d'un site ?
Pour les grands sites, mettez en place un monitoring automatisé des 404 via vos logs serveur et Search Console. Identifiez rapidement les pages cassées qui reçoivent encore du trafic ou des backlinks.
Créez un workflow de traitement : pour chaque 404 détectée, décidez si elle mérite une redirection 301 vers du contenu équivalent ou si le code 404 est la réponse appropriée. Priorisez les URL avec backlinks ou trafic résiduel.
- Implémenter un monitoring hebdomadaire des nouvelles erreurs 404 dans Search Console
- Analyser les logs serveur pour identifier les 404 crawlées fréquemment par Googlebot
- Créer des redirections 301 pertinentes pour les pages avec backlinks vers du contenu similaire
- Optimiser votre page 404 personnalisée pour guider les utilisateurs vers du contenu pertinent
- Auditer régulièrement les liens internes cassés avec un crawler type Screaming Frog
💬 Commentaires (0)
Soyez le premier à commenter.