Declaration officielle
Ce qu'il faut comprendre
Quelle est la différence entre les codes d'erreur 404, 410 et 500 pour Google ?
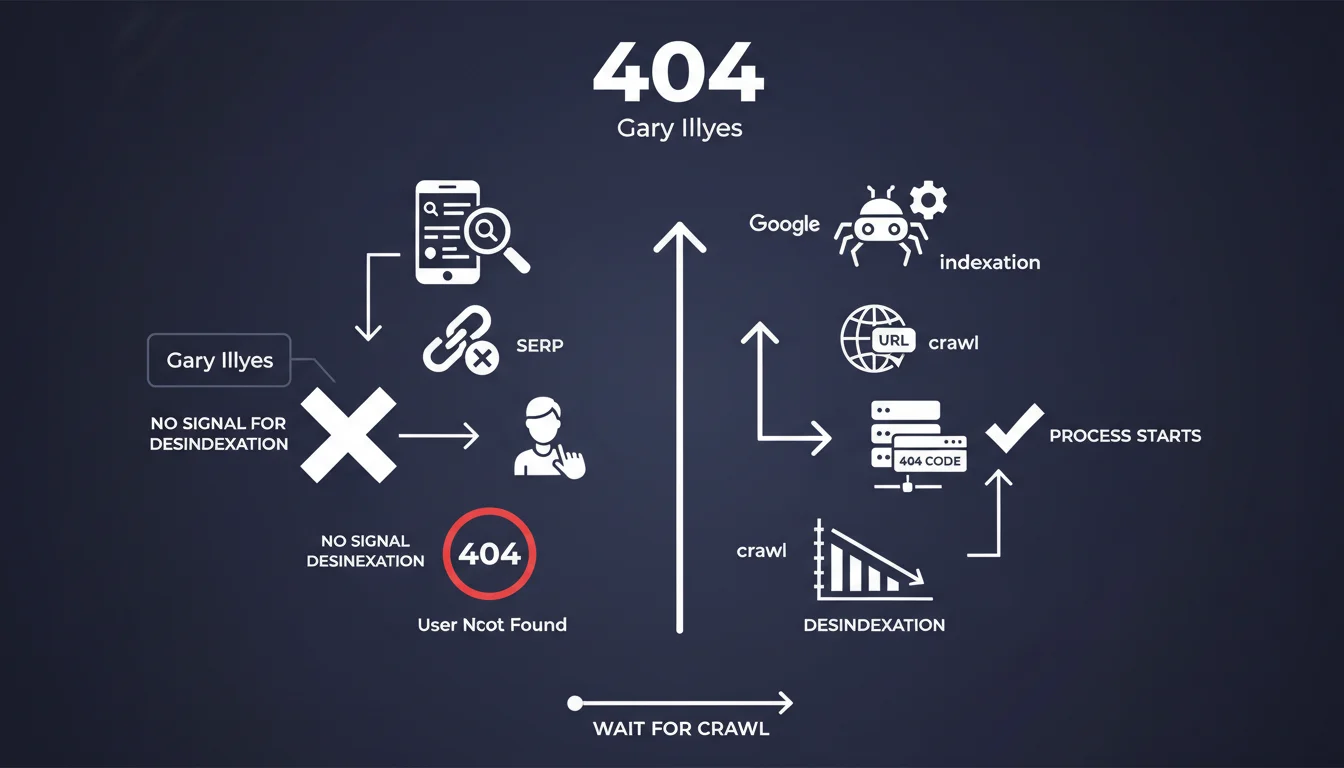
Les codes de statut HTTP jouent un rôle crucial dans la communication avec Googlebot. Le code 404 (Not Found) et le 410 (Gone) indiquent clairement qu'une page n'existe plus, ce qui permet à Google de comprendre qu'il faut retirer cette URL de son index progressivement.
En revanche, le code 500 (Internal Server Error) signale un problème temporaire du serveur. Google ne peut pas interpréter cette erreur comme une disparition définitive de la page. Le moteur considère qu'il s'agit d'un dysfonctionnement passager et continuera à tenter de crawler l'URL jusqu'à obtenir une réponse claire.
Pourquoi Googlebot continue-t-il de visiter des URLs en 404 ?
Contrairement à une idée répandue, Google ne cesse pas immédiatement de crawler une URL qui renvoie un code 404. Tant qu'un signal externe pointe vers cette adresse - généralement un lien provenant d'un autre site - le robot continuera ses tentatives de crawl dans le temps.
Cette information révèle qu'il n'existe pas de mécanisme de pré-vérification qui exclurait automatiquement les URLs disparues du planning de crawl. Googlebot fonctionne plutôt sur la base des signaux qu'il reçoit de l'écosystème web.
Quels sont les points essentiels à retenir de cette déclaration ?
- Les codes 404 et 410 sont les seuls signaux clairs de suppression d'une page pour Google
- Un code 500 ne permet pas la désindexation et gaspille le crawl budget
- Google continue de crawler les URLs en 404 tant qu'il existe des liens pointant vers elles
- Il n'y a pas de liste noire automatique des URLs supprimées dans le processus de crawl
- La persistance des backlinks maintient l'URL dans le circuit de crawl de Googlebot
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
L'observation sur le terrain confirme totalement ce comportement. Les logs serveurs montrent effectivement que Googlebot revient régulièrement sur des URLs en 404, parfois pendant des mois voire des années. Cette persistance est directement corrélée à la présence de backlinks actifs.
Cette révélation a une implication majeure : chaque URL en erreur qui reçoit encore des liens externes consomme du crawl budget inutilement. Pour les sites avec des milliers de pages, ce gaspillage peut impacter significativement la capacité de Google à découvrir et indexer le contenu réellement important.
Quelles nuances faut-il apporter à cette information ?
La fréquence de crawl des URLs en 404 n'est pas constante. Google réduit progressivement la priorité de ces pages, mais ne les abandonne jamais totalement. Plus une URL a reçu de signaux d'autorité par le passé, plus Google mettra du temps à espacer ses visites.
Il est également important de noter que cette logique s'applique différemment selon la qualité et la fraîcheur des backlinks. Une URL en 404 citée par un site d'autorité majeur sera crawlée plus fréquemment qu'une page avec quelques liens obsolètes.
Dans quels cas cette règle peut-elle poser problème ?
Pour les sites ayant subi une refonte majeure ou une migration, des centaines voire milliers d'anciennes URLs peuvent rester dans le circuit de crawl. Si ces pages ne sont pas correctement redirigées, elles drainent le crawl budget et ralentissent la découverte des nouvelles pages.
Les sites de contenu actualisé régulièrement, comme les médias ou les e-commerces avec des produits saisonniers, sont particulièrement concernés. Le volume de pages obsolètes peut devenir un frein significatif à la performance SEO globale du site.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser la gestion des erreurs 404 ?
La première action consiste à identifier les URLs en 404 qui reçoivent encore des backlinks. Utilisez la Google Search Console, des outils comme Ahrefs ou Majestic pour détecter ces liens entrants qui maintiennent vos anciennes pages dans le circuit de crawl.
Pour chaque URL en 404 avec des backlinks, deux options s'offrent à vous : mettre en place une redirection 301 vers le contenu le plus pertinent, ou contacter les webmasters des sites sources pour demander la mise à jour du lien. La redirection est généralement plus pragmatique et rapide.
Ne laissez jamais une erreur 500 persister sur des URLs importantes. Ce code empêche la désindexation et maintient Google dans l'incertitude. Transformez systématiquement ces erreurs en 404 ou 410 si la page a définitivement disparu.
Quelles erreurs faut-il absolument éviter dans la gestion des codes d'erreur ?
L'erreur la plus courante est de créer des soft 404, c'est-à-dire des pages qui renvoient un code 200 (succès) tout en affichant un message d'erreur. Google déteste cette pratique qui l'induit en erreur et peut pénaliser votre site.
Évitez également les redirections massives vers la page d'accueil. Si une page n'a pas de contenu équivalent, il vaut mieux retourner un vrai 404 plutôt qu'une redirection non pertinente qui dégrade l'expérience utilisateur et dilue votre structure de liens internes.
N'utilisez pas le code 410 (Gone) par défaut. Réservez-le aux pages que vous voulez supprimer rapidement de l'index, comme du contenu sensible ou obsolète. Pour une suppression classique, le 404 suffit amplement.
Comment auditer et surveiller efficacement les erreurs de son site ?
Mettez en place un monitoring régulier via la Search Console pour identifier les nouvelles erreurs 404. Créez un tableau de bord mensuel listant les URLs en erreur avec leur volume de backlinks et leur historique de trafic.
Analysez vos logs serveurs pour comprendre le comportement réel de Googlebot sur vos erreurs 404. Cette analyse révèle quelles URLs consomment le plus de crawl budget inutilement et méritent une action prioritaire.
- Auditer toutes les URLs en 404 qui reçoivent encore des backlinks externes
- Mettre en place des redirections 301 vers du contenu pertinent et équivalent
- Corriger immédiatement toutes les erreurs 500 en 404 ou 410 selon le cas
- Éliminer les soft 404 qui renvoient un code 200 avec un contenu d'erreur
- Surveiller mensuellement les nouvelles erreurs via la Search Console
- Analyser les logs serveurs pour identifier les URLs qui drainent le crawl budget
- Documenter les redirections dans un fichier centralisé pour éviter les chaînes de redirections
- Éviter les redirections massives vers la page d'accueil sans pertinence
💬 Commentaires (0)
Soyez le premier à commenter.