Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Faut-il vraiment supprimer les balises meta keywords de votre site ?
- □ Faut-il modifier la date lastmod du sitemap à chaque mise à jour mineure ?
- □ Faut-il vraiment séparer les sitemaps news et généraux pour éviter les doublons d'URLs ?
- □ Pourquoi Google ignore-t-il votre meta description alors que vous l'avez soigneusement rédigée ?
- □ Faut-il vraiment nettoyer les backlinks spammés de votre profil de liens ?
- □ Faut-il encore optimiser la densité de mots-clés pour le SEO ?
- □ Le désaveu de liens suffit-il à récupérer vos positions perdues après une pénalité ?
- □ Pourquoi les redirections 301 restent-elles le nerf de la guerre lors d'un changement de domaine ?
- □ Faut-il vraiment avoir le même contenu sur mobile et desktop pour l'indexation mobile-first ?
- □ Faut-il vraiment demander la suppression des URLs redirigées de l'index Google ?
- □ Vérifier son site dans Search Console améliore-t-il vraiment son référencement ?
- □ Pourquoi Google refuse-t-il le contenu multilingue dynamique sur une même URL ?
- □ Que se passe-t-il quand vos liens hreflang ne se valident pas tous ?
- □ Les liens footer « Made by X » sont-ils vraiment sans danger pour votre SEO ?
- □ Comment configurer correctement les balises canonical et alternate pour un site m-dot ?
- □ Les données EXIF des images sont-elles inutiles pour le SEO ?
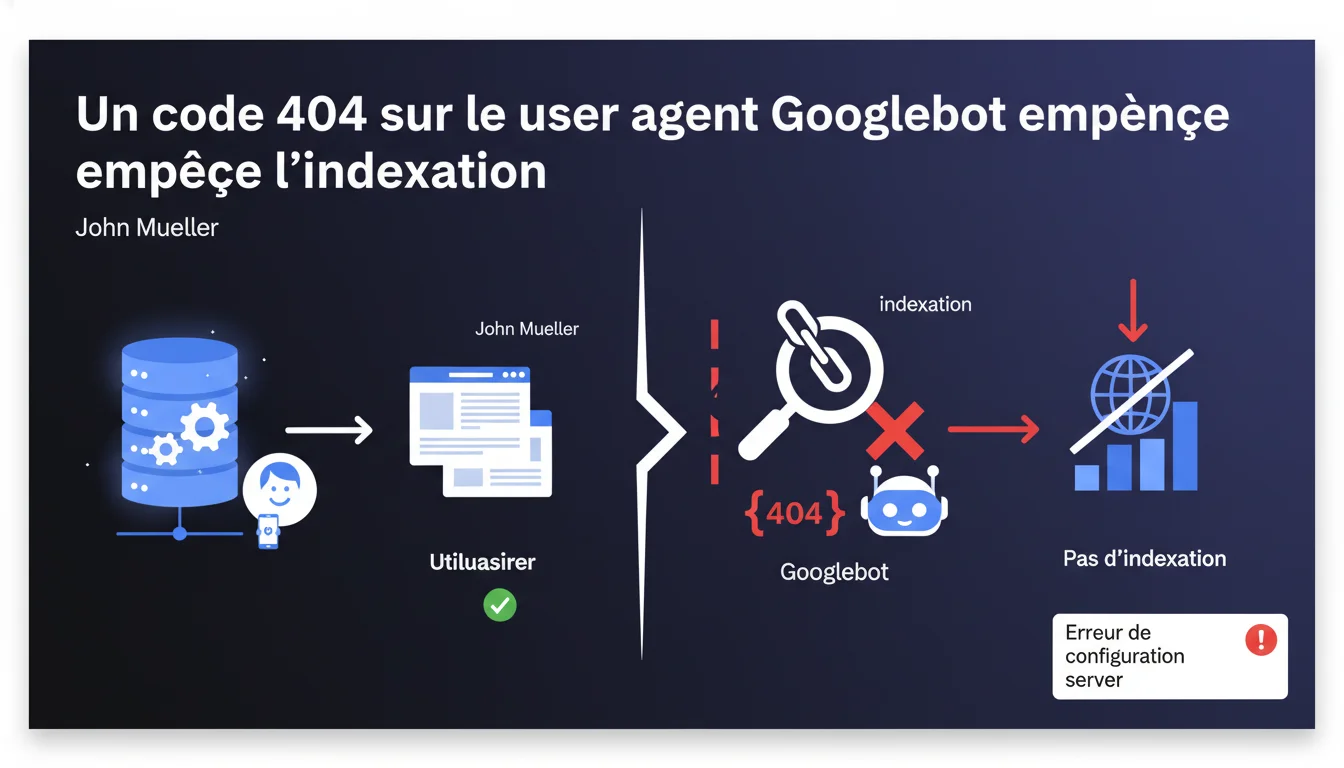
Si votre serveur retourne un code 404 spécifiquement au user agent Googlebot alors que les visiteurs normaux accèdent à la page sans problème, Google considère que cette page n'existe pas et refuse de l'indexer. C'est une erreur de configuration serveur qui peut avoir des conséquences dramatiques sur votre visibilité.
Ce qu'il faut comprendre
Qu'est-ce qu'un code 404 ciblé sur Googlebot ?
Certains serveurs ou systèmes de sécurité détectent le user agent de Googlebot et lui renvoient un code HTTP 404 alors que les navigateurs classiques accèdent normalement au contenu. Cette pratique, souvent involontaire, résulte d'une mauvaise configuration — un firewall trop strict, une règle .htaccess mal rédigée, ou un système anti-bot qui bloque Googlebot par erreur.
Le problème ? Google ne peut pas faire la différence entre une vraie page inexistante et cette situation bancale. Quand il reçoit un 404, il prend l'information au pied de la lettre et retire la page de l'index ou l'empêche d'y entrer.
Pourquoi Google ne détecte-t-il pas cette incohérence ?
Google se base sur ce que son crawler voit — point final. Si Googlebot rencontre un 404, il n'a aucun moyen technique de savoir que les utilisateurs, eux, voient la page. Il n'analyse pas ce qui se passe côté navigateur classique pour vérifier la cohérence.
Cette règle découle d'une logique simple : Google ne peut pas indexer ce qu'il ne peut pas voir. Si vous bloquez volontairement ou accidentellement l'accès à Googlebot, vous sabotez votre propre référencement.
Comment cette situation se produit-elle concrètement ?
Plusieurs scénarios classiques mènent à ce problème. Un plugin de sécurité WordPress trop zélé qui considère Googlebot comme un bot malveillant. Un CDN ou un WAF (Web Application Firewall) configuré pour bloquer certains user agents jugés suspects. Une règle serveur qui interdit l'accès aux crawlers pour « économiser de la bande passante ».
Parfois, c'est un développeur qui a mis en place un système de cloaking inversé sans en mesurer les conséquences — en croyant bien faire pour protéger le site des scrapers, il a aussi bloqué Google.
- Un code 404 ciblé uniquement sur Googlebot empêche toute indexation de la page concernée
- Google ne peut pas détecter l'incohérence entre ce que voit son bot et ce que voient les utilisateurs
- Cette situation résulte souvent d'une mauvaise configuration de sécurité ou d'un firewall trop strict
- Le résultat est identique à celui d'une vraie page 404 : désindexation ou non-indexation
Avis d'un expert SEO
Cette règle est-elle vraiment appliquée sans exception ?
Oui, et c'est l'un des rares points sur lesquels Google ne transige jamais. Si Googlebot reçoit un 404, la page est considérée comme inexistante — même si Search Console ou d'autres outils montrent que des utilisateurs y accèdent. Google n'a aucun mécanisme de vérification croisée pour comparer le comportement serveur entre différents user agents.
Sur le terrain, on observe que ce type d'erreur passe souvent inaperçu pendant des semaines, voire des mois. Pourquoi ? Parce que les propriétaires de sites testent leurs pages avec leur navigateur et constatent que tout fonctionne. Ils ne pensent pas à vérifier ce que voit Googlebot via l'outil d'inspection d'URL de Search Console.
Quels sont les pièges les plus fréquents observés ?
Le premier piège : les systèmes de sécurité qui bloquent par défaut tous les crawlers, y compris les légitimes. Certains hébergeurs proposent des configurations « anti-bot » clé en main qui ne distinguent pas Googlebot des scrapers malveillants.
Deuxième piège : les règles serveur mal testées. Un développeur ajoute une condition sur le user agent pour bloquer un bot spécifique, mais utilise une regex trop large qui capture aussi Googlebot. Exemple classique : bloquer tous les user agents contenant « bot » sans exception pour les crawlers légitimes.
Comment détecter ce problème avant qu'il ne cause des dégâts ?
La méthode la plus fiable reste l'outil d'inspection d'URL dans Google Search Console. Il simule précisément ce que voit Googlebot et affiche le code HTTP retourné, ainsi que le rendu de la page. Si vous obtenez un 404 là alors que la page s'affiche normalement dans votre navigateur, vous tenez votre coupable.
Autre option : utiliser un user agent switcher dans votre navigateur pour simuler Googlebot et observer le comportement du serveur. Mais cette méthode est moins précise car elle ne reproduit pas exactement les conditions réelles de crawl.
Impact pratique et recommandations
Que faut-il vérifier immédiatement sur votre site ?
Testez vos pages les plus stratégiques avec l'outil d'inspection d'URL de Search Console. Concentrez-vous sur les pages qui génèrent du trafic organique ou celles qui ont mystérieusement disparu des résultats de recherche. Comparez le code HTTP retourné à Googlebot avec ce que vous obtenez dans votre navigateur.
Examinez les logs serveur pour détecter les requêtes de Googlebot. Si vous voyez des 404 ou des 403 dans les logs alors que ces pages sont accessibles pour les visiteurs normaux, vous avez identifié le problème. Cherchez les patterns : est-ce toutes les pages, ou seulement certaines sections du site ?
Quelles configurations corriger en priorité ?
Désactivez temporairement vos plugins de sécurité ou vos règles firewall pour tester. Si l'indexation reprend, c'est que le problème vient de là. Configurez ensuite des exceptions explicites pour Googlebot dans votre système de sécurité — la plupart des solutions modernes permettent de whitelister les crawlers légitimes.
Vérifiez vos fichiers .htaccess et les règles nginx/Apache. Cherchez les directives qui bloquent ou redirigent selon le user agent. Si vous bloquez des bots, utilisez une liste blanche pour autoriser explicitement les crawlers des moteurs de recherche majeurs.
Comment éviter que ce problème ne se reproduise ?
Mettez en place un monitoring régulier via Search Console. Configurez des alertes pour être prévenu en cas de hausse brutale des erreurs 404 ou 403. Surveillez aussi vos positions sur les requêtes stratégiques — une chute soudaine peut signaler un problème d'indexation.
Documentez toutes les règles serveur qui touchent au user agent. Quand un développeur modifie une configuration, il doit systématiquement tester l'impact sur Googlebot. Incluez ce test dans votre checklist de déploiement.
- Tester les pages stratégiques avec l'outil d'inspection d'URL de Search Console
- Analyser les logs serveur pour repérer les codes 404/403 retournés spécifiquement à Googlebot
- Désactiver temporairement les plugins de sécurité pour identifier le responsable
- Configurer des exceptions pour whitelister Googlebot dans vos systèmes de protection
- Vérifier et nettoyer les règles .htaccess ou nginx qui filtrent par user agent
- Mettre en place un monitoring Search Console avec alertes sur les erreurs d'exploration
- Documenter toutes les règles serveur liées aux user agents
- Inclure un test Googlebot dans votre processus de déploiement
❓ Questions frequentes
Est-ce que retourner un 403 à Googlebot au lieu d'un 404 change quelque chose ?
Peut-on utiliser le cloaking pour servir du contenu différent à Googlebot et aux utilisateurs ?
Comment vérifier que mon CDN ne bloque pas Googlebot par erreur ?
Un plugin WordPress de sécurité peut-il provoquer ce problème sans que je le sache ?
Si je corrige l'erreur, combien de temps faut-il pour que Google réindexe mes pages ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 31/01/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.