Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Les liens sortants de sites pénalisés sont-ils vraiment ignorés par Google ?
- □ Faut-il abandonner définitivement les annuaires et le bookmarking social pour son SEO ?
- □ Google ignore-t-il vraiment les liens spam automatiquement ?
- □ Faut-il vraiment utiliser l'outil de désaveu de liens Google ou simplement les ignorer ?
- □ Le choix de votre CMS et du langage de programmation affecte-t-il vraiment votre SEO ?
- □ Les mots-clés dans les URL ont-ils vraiment un impact sur le référencement ?
- □ La profondeur de l'URL des images bloque-t-elle vraiment le crawl de Googlebot ?
- □ Les données Search Console reflètent-elles vraiment ce que voient vos utilisateurs ?
- □ Faut-il abandonner le dynamic rendering pour le SEO ?
- □ Faut-il vraiment optimiser les noms de fichiers images pour le SEO ?
- □ Le schema markup invalide pénalise-t-il vraiment votre référencement ?
- □ Faut-il vraiment se préoccuper de la différence entre redirections 301 et 302 ?
- □ Le contenu boilerplate étendu pénalise-t-il vraiment votre référencement ?
- □ Un changement de domaine peut-il vraiment se faire sans perte de trafic SEO ?
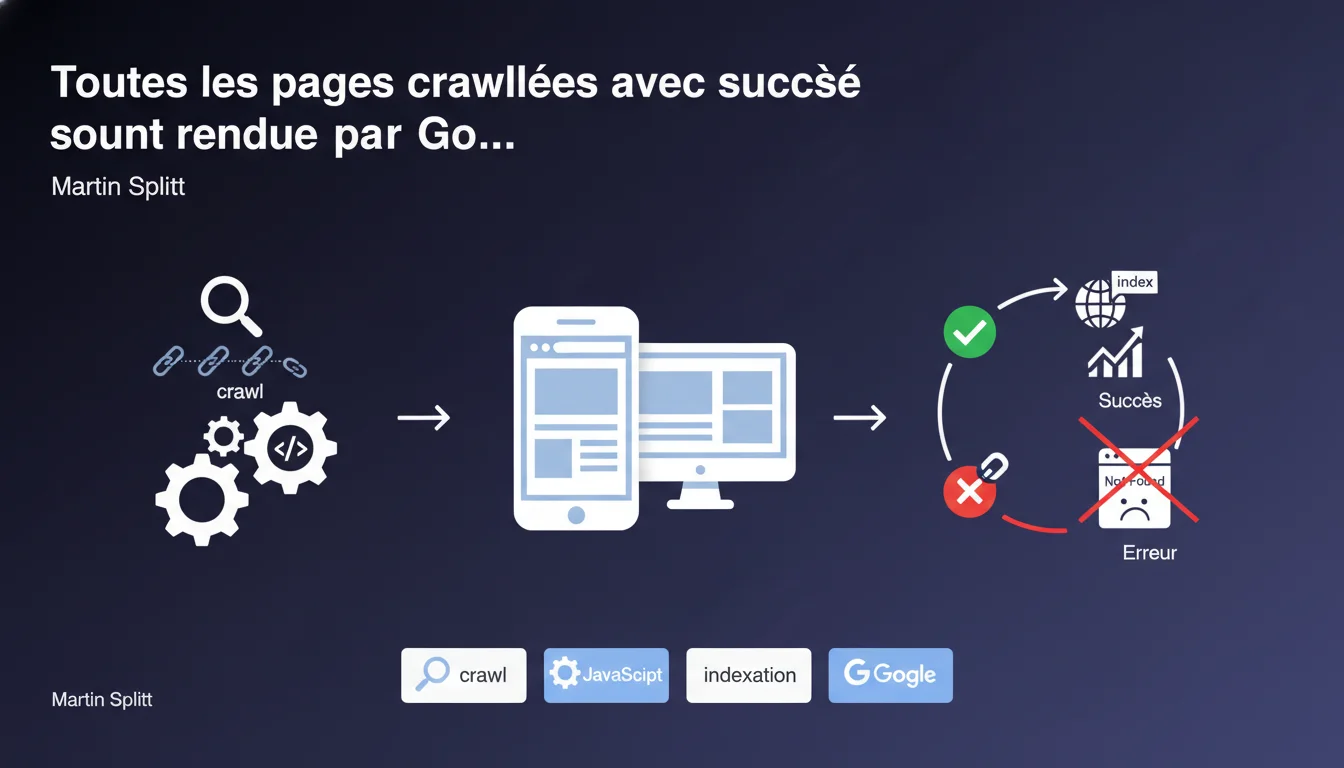
Google affirme que toutes les pages correctement crawlées sont rendues par Googlebot — seules les erreurs (404, 5xx) échappent au rendu. Le rendu JavaScript est intégré au processus d'indexation normal, ce n'est plus une étape optionnelle ou secondaire. Concrètement, si votre page se charge sans erreur HTTP, elle sera rendue, point.
Ce qu'il faut comprendre
Cette déclaration de Martin Splitt tranche avec des idées reçues tenaces : non, Googlebot ne se contente pas d'analyser le HTML brut avant de passer son chemin. Le rendu JavaScript fait partie du pipeline d'indexation standard.
Autrement dit, si votre page charge correctement (code 200), Google exécutera le JS, attendra que le DOM se stabilise, puis indexera le contenu généré dynamiquement. Les seules exceptions sont les pages qui retournent des erreurs HTTP — 404, 503, timeouts sévères.
Le rendu JavaScript est-il vraiment systématique pour toutes les pages crawlées ?
Oui, selon Splitt. Toute page qui répond avec un code de succès (2xx ou 3xx redirigé vers 2xx) passe par la phase de rendu. Cela signifie que le crawl budget n'impacte pas directement le rendu : si Googlebot visite la page, il la rend.
Attention toutefois — « rendu » ne signifie pas « rendu instantané ». Il peut y avoir un délai entre le crawl initial (HTML brut) et le rendu complet (JS exécuté). Ce décalage peut influencer la vitesse à laquelle les mises à jour sont visibles dans l'index.
Qu'est-ce qui empêche une page d'être rendue, concrètement ?
Les erreurs HTTP sont le bloqueur principal. Une 404, une 5xx, un timeout réseau — tout ce qui empêche Googlebot de récupérer le contenu HTML de base stoppe le processus avant même le rendu.
Les pages bloquées par robots.txt ne sont jamais crawlées, donc jamais rendues. Les pages orphelines ou mal maillées peuvent être crawlées tardivement ou jamais, ce qui retarde ou annule le rendu. Enfin, si le JavaScript plante ou boucle indéfiniment, le rendu peut échouer ou s'arrêter prématurément — mais Google considère techniquement qu'il a *tenté* de rendre la page.
Pourquoi cette précision sur le « processus normal » est-elle importante ?
Parce qu'elle enterre définitivement le mythe selon lequel Google n'indexerait pas le contenu généré en JS « par défaut ». Le rendu n'est pas un bonus réservé aux gros sites — c'est la norme.
Cela dit, « normal » ne veut pas dire « infaillible ». Les sites avec du JS mal optimisé (scripts lourds, ressources bloquées, lazy-loading agressif) peuvent subir un rendu partiel ou incomplet. Google *essaie* de tout rendre, mais la qualité du résultat dépend de votre implémentation technique.
- Toute page crawlée avec succès (2xx) est rendue par Googlebot — le rendu JS est intégré au processus d'indexation standard
- Seules les erreurs HTTP (404, 5xx, timeouts) empêchent le rendu d'une page
- Le crawl budget n'affecte pas directement le rendu — si Google visite la page, il la rend
- Un délai peut exister entre crawl et rendu complet, impactant la vitesse d'indexation des mises à jour
- Le rendu peut échouer ou être partiel si le JS est mal optimisé (scripts lourds, ressources bloquées, erreurs côté client)
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Globalement, oui. Les tests avec Google Search Console (outil d'inspection d'URL) montrent effectivement que Googlebot rend la plupart des pages — même celles avec du React ou Vue lourd. Les captures d'écran du rendu live dans GSC confirment que le JS est exécuté.
Mais voilà où ça coince : le rendu « systématique » ne garantit pas un rendu *complet* ou *rapide*. J'ai vu des sites où des éléments chargés via Intersection Observer ou après un délai asynchrone n'apparaissent jamais dans le snapshot de Google. Techniquement, la page a été rendue — mais pas assez longtemps pour capturer tout le contenu.
[A vérifier] : Google ne communique pas de SLA clair sur la durée d'attente avant le snapshot final. Certains parlent de 5 secondes, d'autres de 10. En réalité, ça varie probablement selon le crawl budget alloué au domaine et la charge serveur.
Quelles nuances faut-il apporter à cette affirmation ?
« Toutes les pages crawlées avec succès » — OK, mais qu'est-ce qu'un crawl « avec succès » ? Un 200 HTML vide mais qui charge du contenu en JS 3 secondes plus tard, c'est un succès HTTP… mais un échec SEO si Google snapshot avant que le contenu soit visible.
Autre point : Splitt ne mentionne pas les pages avec JavaScript obfusqué, erreurs console critiques, ou boucles de redirections côté client. Ces cas techniques peuvent provoquer un rendu partiel ou un abandon silencieux. Google « tente » de rendre, mais si le script plante, l'indexation sera incomplète — et vous n'aurez aucune alerte claire dans GSC.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Les pages bloquées par robots.txt ou meta robots noindex ne sont jamais rendues (ou ignorées après rendu). Les pages orphelines sans liens internes peuvent être découvertes via sitemaps, mais si Googlebot ne les visite jamais, elles ne seront jamais rendues non plus.
Les soft 404 (pages 200 avec contenu vide ou « page non trouvée » en JS) sont techniquement rendues, mais Google peut les interpréter comme des erreurs après analyse. Enfin, les pages sous connexion HTTPS défaillante ou certificat invalide peuvent être refusées avant le crawl — donc jamais rendues.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur son site ?
Première étape : Google Search Console, outil d'inspection d'URL. Testez vos pages critiques et comparez le rendu live avec ce que vous voyez dans le navigateur. Si des blocs de contenu manquent, c'est que le rendu a échoué ou s'est arrêté trop tôt.
Ensuite, vérifiez les ressources bloquées dans GSC (CSS, JS, images). Si des fichiers critiques sont bloqués par robots.txt, le rendu sera incomplet. Corrigez ces blocages immédiatement.
Enfin, traquez les erreurs JavaScript dans la console. Un script qui plante peut stopper le rendu avant que tout le contenu soit visible. Utilisez des outils comme Lighthouse ou GTmetrix pour identifier les erreurs critiques côté client.
Quelles erreurs éviter absolument ?
Ne comptez jamais uniquement sur le lazy-loading natif ou agressif pour charger du contenu critique. Si Googlebot snapshot avant le trigger, le contenu sera invisible. Privilégiez le SSR (Server-Side Rendering) ou le prerendering pour les pages stratégiques.
Évitez de bloquer les ressources JS/CSS essentielles via robots.txt — c'est une erreur courante qui sabote le rendu. Et ne faites pas confiance aveuglément au « Google rend tout » : testez, validez, itérez.
Méfiez-vous aussi des redirections JavaScript côté client (window.location) sans équivalent HTTP. Google peut les suivre… ou pas. Préférez toujours une redirection 301/302 côté serveur.
Comment optimiser son site pour garantir un rendu complet ?
Implémentez du Server-Side Rendering (SSR) ou du Static Site Generation (SSG) pour les pages à fort enjeu SEO. Cela garantit que le contenu est disponible dans le HTML brut, sans dépendre du JS.
Si vous restez en CSR (Client-Side Rendering), assurez-vous que le contenu critique s'affiche en moins de 3 secondes après le chargement initial. Testez avec l'outil « Mobile-Friendly Test » de Google pour voir ce que Googlebot capture réellement.
Enfin, utilisez les structured data (JSON-LD) directement dans le HTML initial plutôt qu'injectés en JS après coup. Google peut les indexer même en JS, mais le HTML brut reste plus fiable.
- Tester le rendu de vos pages critiques via l'outil d'inspection d'URL dans GSC
- Vérifier qu'aucune ressource JS/CSS critique n'est bloquée par robots.txt
- Traquer les erreurs JavaScript côté client qui peuvent stopper le rendu
- Privilégier SSR/SSG pour les pages stratégiques plutôt que du CSR pur
- Garantir que le contenu critique apparaît en moins de 3 secondes après le chargement
- Injecter les structured data directement dans le HTML initial, pas uniquement en JS
- Éviter le lazy-loading agressif pour le contenu essentiel au-dessus de la ligne de flottaison
- Utiliser des redirections HTTP (301/302) plutôt que JavaScript pour les changements d'URL
Le rendu JavaScript est désormais la norme chez Google — mais cette norme repose sur une implémentation technique solide de votre côté. Les sites qui négligent l'optimisation JS, bloquent des ressources critiques ou comptent sur un lazy-loading hasardeux risquent un rendu partiel… même si Google « essaie » de tout indexer.
Ces optimisations techniques — SSR, gestion des ressources, performance JS — peuvent rapidement devenir complexes, surtout sur des architectures modernes (React, Vue, Next.js). Si vous constatez des écarts entre ce que vous voyez et ce que Google indexe, il peut être judicieux de faire appel à une agence SEO spécialisée en JavaScript SEO pour un audit approfondi et un accompagnement sur mesure. Parce que le diable se cache toujours dans les détails d'implémentation.
❓ Questions frequentes
Googlebot rend-il les pages même si elles utilisent un framework JavaScript moderne comme React ou Vue ?
Si une page retourne un code 200 mais affiche du contenu vide en HTML brut, sera-t-elle quand même indexée ?
Les pages bloquées par robots.txt sont-elles rendues par Google ?
Combien de temps Google attend-il avant de capturer le rendu final d'une page ?
Une erreur JavaScript côté client peut-elle empêcher l'indexation d'une page ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/05/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.