Declaration officielle
Autres déclarations de cette vidéo 4 ▾
- □ Les nouveaux types de données structurées Google sont-ils vraiment utiles pour votre SEO ?
- □ Quelles sont les nouvelles fonctionnalités Search Console que vous devez absolument maîtriser ?
- □ Pourquoi Google publie-t-il des ressources spécifiques sur le SEO local maintenant ?
- □ Google publie-t-il enfin de la documentation claire sur les LLM et leur impact SEO ?
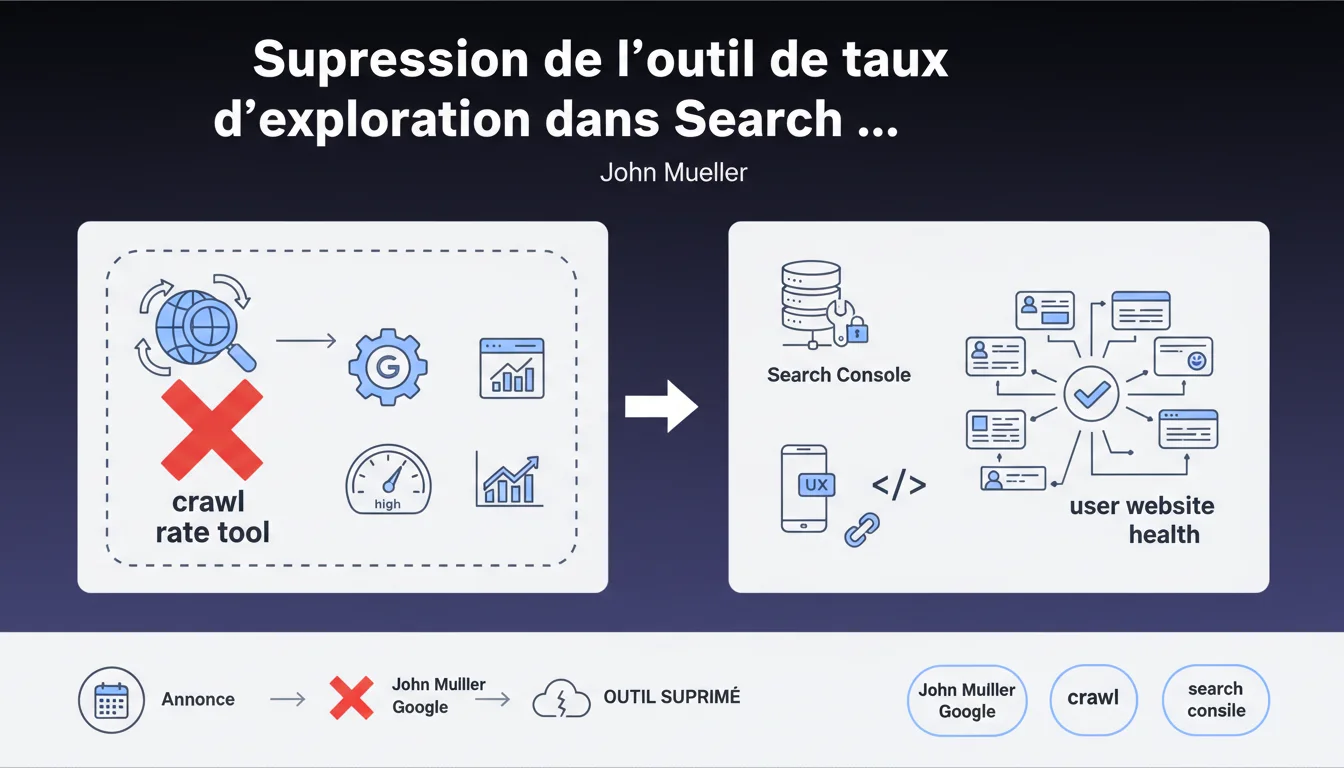
Google retire l'outil de taux d'exploration de la Search Console. Les webmasters n'auront plus accès à cet outil historique permettant de visualiser et limiter la fréquence de crawl de Googlebot. Cette suppression s'inscrit dans une logique de simplification des outils, Google considérant que la gestion automatique du crawl budget est désormais suffisamment performante.
Ce qu'il faut comprendre
Que permettait réellement cet outil de taux d'exploration ?
L'outil de taux d'exploration offrait aux webmasters une visibilité sur la fréquence de crawl de Googlebot sur leur site. Plus précisément : un graphique montrant le nombre de requêtes par jour, des statistiques sur la vitesse de téléchargement, et la possibilité de plafonner le taux d'exploration.
Cette fonction de limitation était particulièrement utilisée par les sites avec des infrastructures sensibles — serveurs anciens, budgets serveur limités, pics de trafic imprévisibles. En bridant Googlebot, on évitait qu'il ne surcharge le serveur lors de phases d'exploration intensive.
Qu'est-ce qui remplace cet outil dans Search Console ?
Rien de direct. Google mise désormais sur son algorithme de gestion automatique du crawl budget. Le moteur ajuste lui-même la fréquence en fonction des signaux qu'il capte : temps de réponse du serveur, erreurs 5xx, disponibilité générale.
Les rapports de couverture et les logs serveur restent les principaux moyens de surveiller l'activité de Googlebot. Mais aucun contrôle manuel n'est proposé en remplacement — c'est un pari sur l'efficacité de l'automatisation.
Cette suppression concerne-t-elle tous les sites de la même manière ?
Non. Les petits sites avec peu de pages ne verront aucune différence — ils n'utilisaient probablement jamais cet outil. Pour eux, le crawl budget n'a jamais été un enjeu critique.
En revanche, les gros sites avec millions de pages, les plateformes e-commerce massives ou les sites à faible capacité serveur perdent un levier de contrôle. Même si Google affirme que son automatisation fonctionne bien, certains cas d'usage spécifiques pouvaient justifier une limitation manuelle.
- L'outil permettait de visualiser l'intensité du crawl au jour le jour
- Il donnait la possibilité de brider Googlebot en cas de surcharge serveur
- Google table désormais sur une gestion 100% automatique du taux d'exploration
- Les sites avec infrastructures limitées sont les plus impactés par cette suppression
- Aucun outil de remplacement direct n'est proposé dans Search Console
Avis d'un expert SEO
Cette décision est-elle cohérente avec l'évolution de Search Console ?
Oui, et c'est même logique dans la continuité. Google a progressivement retiré tous les leviers de contrôle manuel qu'il juge redondants avec ses systèmes automatiques. L'outil de désaveu de liens est passé au second plan, certaines options de ciblage international ont été simplifiées — la tendance est claire.
Le message sous-jacent : faites-nous confiance, nos algorithmes gèrent mieux que vous. Dans 90% des cas, c'est probablement vrai — mais les 10% restants, ceux qui ont des besoins spécifiques, perdent une option.
Les cas limites sont-ils vraiment pris en compte par l'automatisation ?
Soyons honnêtes : on manque de données concrètes sur la manière dont Googlebot ajuste son comportement face à des configurations atypiques. Un site avec un serveur mutualisé fragile, une base de données qui sature facilement, ou des contraintes budgétaires strictes — ces situations existent.
Google affirme que son système détecte automatiquement les signes de surcharge. Mais quid du délai de réaction ? Si Googlebot provoque un pic de charge avant de s'en rendre compte, le mal est fait. [A vérifier] sur le terrain : est-ce que les sites à faible capacité observent réellement une adaptation fine du crawl, ou subissent-ils des à-coups ?
Faut-il anticiper d'autres suppressions d'outils dans Search Console ?
Probablement. Google suit une logique de simplification et de consolidation de ses interfaces. Tout outil jugé peu utilisé ou redondant avec un système automatique est candidat au retrait.
Les prochaines cibles potentielles ? Les fonctionnalités de paramétrage avancées qui concernent une minorité d'utilisateurs. Google privilégie une interface accessible au plus grand nombre — ce qui est compréhensible, mais laisse parfois les experts avec moins de contrôle granulaire.
Impact pratique et recommandations
Que faire si vous utilisiez cet outil pour limiter le crawl ?
D'abord, évaluez si le bridage était vraiment nécessaire. Dans beaucoup de cas, c'était une précaution par défaut plus qu'une nécessité technique. Si votre serveur encaisse le trafic sans broncher, vous n'avez rien à changer.
Si vous aviez effectivement des raisons de limiter Googlebot — serveur sous-dimensionné, coûts d'infrastructure — vous devez désormais travailler côté serveur. Optimisation du temps de réponse, cache agressif, CDN pour les ressources statiques. L'objectif : que votre infrastructure tienne la charge sans avoir besoin de brider le moteur.
Comment surveiller l'activité de Googlebot sans cet outil ?
Les logs serveur deviennent encore plus indispensables. C'est votre seule source de vérité sur ce que fait réellement Googlebot : fréquence de crawl, pages visitées, codes de statut retournés.
Mettez en place un monitoring qui vous alerte en cas de pic anormal de requêtes ou de charge serveur inhabituelle. Si Googlebot devient trop gourmand, vous le verrez dans vos métriques — et vous pourrez agir en conséquence (optimisation technique, scaling serveur).
Quelles erreurs éviter face à cette suppression ?
Ne paniquez pas et ne cherchez pas de solutions alternatives bancales. Certains réflexes sont contre-productifs : bloquer Googlebot via robots.txt pour réduire le crawl (vous perdez l'indexation), ralentir artificiellement le serveur pour que Google se calme (vous dégradez l'expérience utilisateur), ou mettre en place des rate limiting agressifs (risque de bloquer aussi de vrais utilisateurs).
L'approche saine : optimisez votre infrastructure pour qu'elle encaisse le crawl naturel de Google. Si ce n'est pas possible avec vos ressources actuelles, c'est un signal qu'il faut revoir l'hébergement ou l'architecture technique.
- Analysez vos logs serveur pour établir un baseline du crawl actuel de Googlebot
- Mettez en place des alertes automatiques sur la charge serveur et le volume de requêtes bot
- Optimisez les temps de réponse et implémentez un cache efficace
- Vérifiez que votre infrastructure peut encaisser le crawl naturel sans limitation
- Documentez les éventuels pics de charge liés au crawl pour identifier des patterns
- Ne bloquez jamais Googlebot via robots.txt pour gérer le taux de crawl
- Envisagez un upgrade d'hébergement si votre serveur sature régulièrement
❓ Questions frequentes
Puis-je encore limiter le taux d'exploration de Googlebot d'une autre manière ?
Cette suppression va-t-elle augmenter la charge serveur sur mon site ?
Les logs serveur suffisent-ils à remplacer l'outil de taux d'exploration ?
Cette décision impacte-t-elle l'indexation de mes pages ?
Google peut-il revenir en arrière et rétablir cet outil ?
🎥 De la même vidéo 4
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.