Declaration officielle
Autres déclarations de cette vidéo 2 ▾
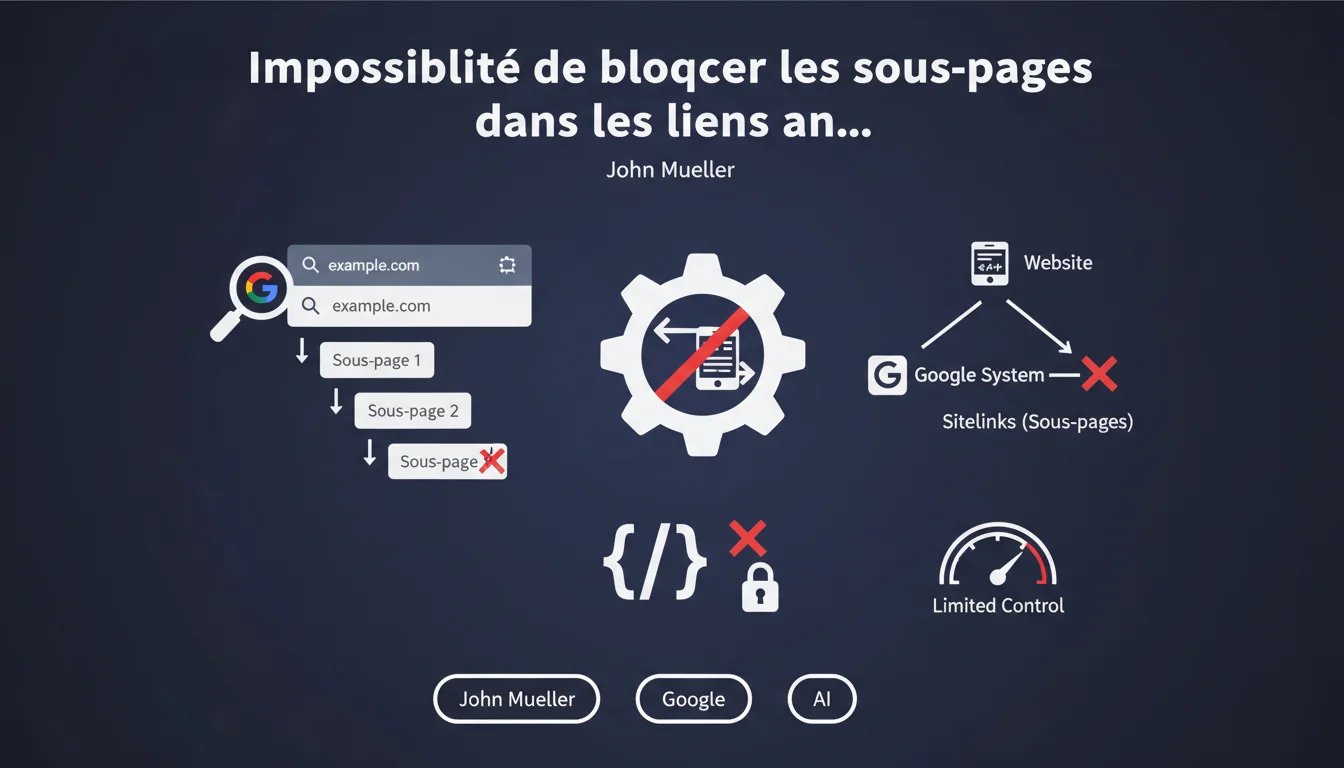
Google ne propose aucun mécanisme pour bloquer une sous-page spécifique des liens annexes (sitelinks). Vous ne pouvez pas empêcher telle ou telle URL d'apparaître sous votre résultat principal. Le contrôle reste entièrement algorithmique, sans levier granulaire côté webmaster.
Ce qu'il faut comprendre
Les liens annexes — ou sitelinks — apparaissent sous certains résultats de recherche pour faciliter la navigation vers des sections clés d'un site. Google les génère automatiquement en se basant sur la structure du site, la popularité des pages et le comportement des utilisateurs.
Mueller confirme ici ce que beaucoup soupçonnaient : il n'existe aucun outil permettant de dire « je ne veux pas que cette page-là apparaisse en sitelink ». L'ancien outil de rétrogradation des sitelinks dans Search Console a été supprimé il y a plusieurs années, et rien ne l'a remplacé.
Pourquoi Google refuse-t-il ce contrôle granulaire ?
La logique de Google repose sur l'expérience utilisateur. L'algorithme choisit les liens qu'il juge les plus utiles pour l'internaute cherchant votre marque ou votre domaine. Offrir un contrôle manuel pourrait dégrader cette expérience — un site pourrait masquer des pages pertinentes pour des raisons commerciales ou stratégiques qui ne servent pas l'utilisateur.
En pratique, cela signifie que si une page « embarassante » ou obsolète remonte en sitelink, vous ne pourrez pas la désactiver d'un clic.
Quels leviers indirects existent-ils malgré tout ?
Même sans contrôle direct, certaines actions influencent la sélection des sitelinks. Une architecture claire, des titres de page pertinents, un maillage interne cohérent et des données structurées bien implémentées orientent l'algorithme.
Supprimer une page, la bloquer via robots.txt ou meta noindex, la déclasser en la retirant du menu principal — ces tactiques fonctionnent, mais elles ont des effets collatéraux sur le référencement global de la page.
- Aucun outil Google pour bloquer un sitelink spécifique
- L'ancien système de rétrogradation a disparu sans remplacement
- L'algorithme privilégie l'expérience utilisateur sur le contrôle éditorial
- Seuls des ajustements indirects (architecture, maillage, noindex) peuvent influencer la sélection
Avis d'un expert SEO
Cette absence de contrôle pose-t-elle un vrai problème opérationnel ?
Honnêtement, dans la majorité des cas, non. Les sitelinks choisis par Google reflètent souvent les pages les plus consultées et les mieux structurées. Quand l'algorithme se trompe, c'est généralement révélateur d'un souci plus profond : architecture bancale, contenus dupliqués, titres de page flous.
Là où ça coince, c'est sur les sites avec des sections temporaires (promos, événements passés) ou des pages techniques (connexion, panier, CGV) qui remontent en sitelink. Google n'a pas toujours le contexte business pour distinguer une page « légitime mais peu désirable en vitrine » d'une page stratégique.
Les solutions de contournement sont-elles vraiment satisfaisantes ?
Passer une page en noindex pour qu'elle disparaisse des sitelinks, c'est tirer au bazooka sur une mouche. Vous perdez le trafic organique de cette page, son jus de lien, sa contribution au crawl budget. Rediriger ou supprimer une URL juste pour nettoyer des sitelinks, c'est sacrifier du potentiel SEO pour un problème cosmétique.
Le vrai levier reste l'optimisation architecturale : hiérarchie HTML propre, breadcrumbs, données structurées BreadcrumbList, ancres de liens internes cohérentes. Mais ces ajustements prennent du temps à produire leurs effets — et rien ne garantit le résultat. [A verifier] : aucune documentation officielle ne précise le poids exact de chaque signal dans la sélection des sitelinks.
Faut-il s'inquiéter d'une page sensible en sitelink ?
Si une page confidentielle (espace client, backoffice) remonte en sitelink, le problème n'est pas l'absence de contrôle des sitelinks. C'est que cette page est indexée alors qu'elle ne devrait pas l'être. Là, noindex ou authentification serveur sont justifiés.
Pour les pages « gênantes mais légitimes » (ancien article, promo expirée), la meilleure stratégie reste de les améliorer ou rediriger plutôt que de chercher à les masquer. Google valorise les sites qui gardent leur contenu à jour — un sitelink obsolète signale souvent un site mal entretenu.
Impact pratique et recommandations
Que faire si un sitelink indésirable apparaît sous mon résultat ?
Première étape : diagnostiquer pourquoi cette page remonte. Vérifiez son volume de clics organiques dans Search Console, son positionnement dans le menu principal, le nombre de liens internes pointant vers elle. Souvent, une page remonte en sitelink parce qu'elle reçoit beaucoup de trafic ou de liens — signe qu'elle est perçue comme importante.
Si la page est obsolète ou peu stratégique, redirigez-la (301) vers une version à jour ou une page parente plus pertinente. Si elle doit rester accessible mais pas en vitrine, retirez-la du menu principal, réduisez les liens internes, aplatissez sa hiérarchie dans le breadcrumb.
Quelles erreurs éviter absolument ?
Ne passez jamais une page en noindex uniquement pour la retirer des sitelinks. Vous la désindexez complètement — perte de trafic, de backlinks, de jus. Ne la bloquez pas non plus en robots.txt si elle contient du contenu utile : Google ne pourra plus en crawler le contenu, ce qui dégrade la compréhension globale de votre site.
Évitez aussi de multiplier les redirections en chaîne pour « cacher » une page. Google suit les redirections, et une page redirigée disparaîtra des sitelinks… mais aussi de l'index. Soyez chirurgical, pas brutal.
Comment optimiser la sélection des sitelinks de manière proactive ?
Travaillez votre architecture sémantique. Utilisez des titres de page (<title>) clairs et distincts. Implémentez les données structurées BreadcrumbList pour signaler la hiérarchie. Organisez votre menu principal pour refléter les priorités business — Google s'en sert comme signal.
Auditez régulièrement les pages qui apparaissent en sitelinks via des recherches de marque. Si une page « surprise » remonte, c'est un indicateur : soit elle mérite sa place et vous devez l'assumer, soit elle signale un déséquilibre dans votre maillage interne ou votre stratégie de contenu.
- Auditer les sitelinks actuels via recherches de marque et Search Console
- Identifier les pages indésirables et comprendre pourquoi elles remontent (trafic, liens internes, position dans le menu)
- Rediriger (301) les pages obsolètes vers des versions à jour ou des parents pertinents
- Réduire le poids des pages gênantes : retrait du menu, moins de liens internes, breadcrumb aplati
- Renforcer les pages stratégiques : titres distincts, données structurées, présence dans le menu, maillage interne solide
- Ne jamais utiliser noindex ou robots.txt uniquement pour masquer un sitelink
- Surveiller l'évolution des sitelinks après chaque refonte ou ajustement architectural
❓ Questions frequentes
Puis-je bloquer une page spécifique des sitelinks avec robots.txt ?
L'ancien outil de rétrogradation des sitelinks dans Search Console existe-t-il encore ?
Si je mets une page en noindex, elle disparaîtra des sitelinks ?
Quels signaux influencent le choix des sitelinks par Google ?
Combien de temps faut-il pour qu'un ajustement architectural modifie les sitelinks ?
🎥 De la même vidéo 2
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 17/07/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.