Declaration officielle
Autres déclarations de cette vidéo 5 ▾
- □ Les opinions Google sur le Web3 reflètent-elles vraiment la position du moteur de recherche ?
- □ Les contenus en communautés privées sont-ils vraiment invisibles pour Google ?
- □ Les créateurs doivent-ils vraiment contrôler ce qui est indexé par Google ?
- □ Pourquoi Google ne peut-il pas indexer les contenus sans URL crawlable ?
- □ Google va-t-il abandonner le crawl traditionnel pour indexer le web social ?
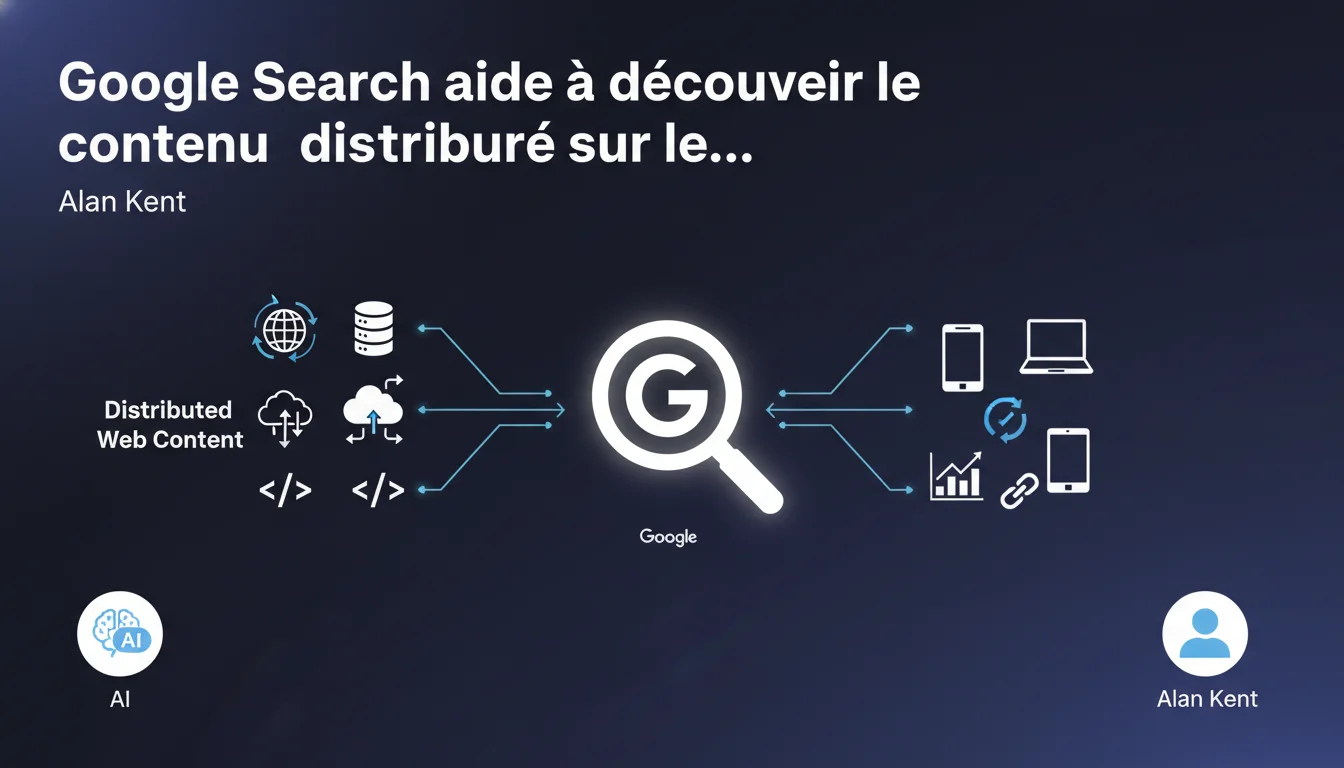
Alan Kent rappelle que Google n'héberge pas le contenu qu'il indexe — il se contente de pointer vers des serveurs distribués partout dans le monde. Le moteur joue un rôle d'aiguilleur, pas d'hébergeur. Pour un professionnel SEO, ça signifie que la qualité de l'infrastructure technique du site reste déterminante pour être trouvé et crawlé efficacement.
Ce qu'il faut comprendre
Cette déclaration arrive dans un contexte où Google est régulièrement accusé de favoriser son propre contenu (featured snippets, People Also Ask, Knowledge Graph) au détriment des sites tiers. Kent recadre : le moteur ne stocke pas les pages, il les indexe et les référence.
Pourquoi Google insiste-t-il sur ce point ?
Parce que la confusion entre indexation et hébergement est fréquente, y compris chez les régulateurs. Dire « Google affiche mon contenu » n'est pas exact : il affiche un lien vers votre serveur. La nuance est juridique autant que technique.
En pratique, ça signifie que si votre serveur est lent, inaccessible ou mal configuré, Google ne peut rien faire pour améliorer l'expérience utilisateur — il redirige simplement vers une ressource défaillante.
Qu'est-ce que ça change pour le SEO au quotidien ?
Cela renforce l'importance de l'infrastructure technique : temps de réponse serveur, CDN, gestion DNS, disponibilité. Google ne compense pas vos faiblesses d'hébergement.
Cela rappelle aussi que le web reste décentralisé par nature. Votre contenu vit sur votre serveur. Google n'est qu'un index géant — pas un CMS centralisé.
- Google ne stocke pas vos pages : il les crawle, les indexe, puis renvoie les utilisateurs vers vos serveurs.
- La qualité de votre infrastructure impacte directement votre visibilité : si le serveur est lent ou instable, le crawl et l'UX en pâtissent.
- Le web reste distribué : chaque site est responsable de son propre hébergement et de sa propre disponibilité.
- Google joue le rôle d'aiguilleur, pas de diffuseur de contenu. Il oriente le trafic, mais ne garantit pas l'expérience une fois l'utilisateur arrivé sur le site.
Avis d'un expert SEO
Cette déclaration correspond-elle vraiment à la réalité observée ?
Oui, techniquement. Google n'héberge pas vos pages HTML complètes. Il en stocke une copie dans son index, certes, mais l'utilisateur est bien redirigé vers votre serveur.
Mais la nuance devient floue avec les featured snippets, AMP, Google Cache, et bientôt l'IA générative. Ces fonctionnalités affichent du contenu directement dans les SERP, sans que l'utilisateur clique vers le site source. Dire que Google « ne fait que diriger » devient alors un euphémisme.
Pourquoi cette communication maintenant ?
Probablement une réponse aux pressions réglementaires autour du monopole de Google. En insistant sur le caractère décentralisé du web, Kent défend l'idée que Google reste un simple intermédiaire — pas un gardien (gatekeeper) qui capte le trafic.
Soyons honnêtes : c'est vrai en théorie, mais de moins en moins en pratique. Quand 60 % des recherches sur mobile se terminent sans clic, on peut difficilement prétendre que Google « dirige vers le contenu distribué ».
Quelle conséquence pour les SEO ?
On ne peut plus compter uniquement sur le trafic organique classique. Il faut aussi optimiser pour les extraits enrichis, les PAA, les carrousels — tout ce qui capte l'attention avant le clic.
Et paradoxalement, ça renforce l'importance de l'infrastructure technique : si Google renvoie bien vers vos serveurs, encore faut-il qu'ils tiennent la charge et répondent vite. Sinon, l'utilisateur repart aussi sec.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur son infrastructure ?
Le temps de réponse serveur (TTFB) doit être inférieur à 200 ms dans l'idéal. Au-delà de 600 ms, vous commencez à perdre des points sur l'expérience utilisateur et potentiellement sur le crawl budget.
Assurez-vous que votre hébergement tient la charge lors des pics de trafic. Un serveur qui tombe au moment où Googlebot passe, c'est un signal négatif direct.
Comment optimiser la relation entre Google et vos serveurs ?
Utilisez un CDN pour distribuer le contenu statique au plus près des utilisateurs. Cela réduit la latence et améliore la disponibilité globale.
Configurez correctement les fichiers robots.txt et sitemap.xml pour guider Googlebot vers vos pages prioritaires sans gaspiller de crawl budget sur des sections inutiles.
Surveillez les erreurs serveur (5xx) dans la Search Console. Une hausse soudaine peut signaler un problème d'infrastructure qui impacte directement votre visibilité.
- Mesurer le TTFB de vos pages principales et l'optimiser en dessous de 200 ms
- Mettre en place un CDN pour réduire la latence géographique
- Vérifier la disponibilité serveur avec un monitoring 24/7 (Uptime Robot, Pingdom, etc.)
- Analyser les logs serveur pour détecter les erreurs 5xx et les corriger rapidement
- Optimiser le crawl budget via robots.txt et sitemap pour prioriser les pages stratégiques
- Tester la réponse serveur sous charge (load testing) pour anticiper les pics de trafic
❓ Questions frequentes
Google stocke-t-il vraiment une copie complète de mes pages ?
Un serveur lent peut-il vraiment faire baisser mon classement ?
Est-ce que Google compense les problèmes d'hébergement ?
Pourquoi Google insiste-t-il sur le caractère décentralisé du web ?
Les featured snippets contredisent-ils cette déclaration ?
🎥 De la même vidéo 5
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/05/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.