Declaration officielle
Ce qu'il faut comprendre
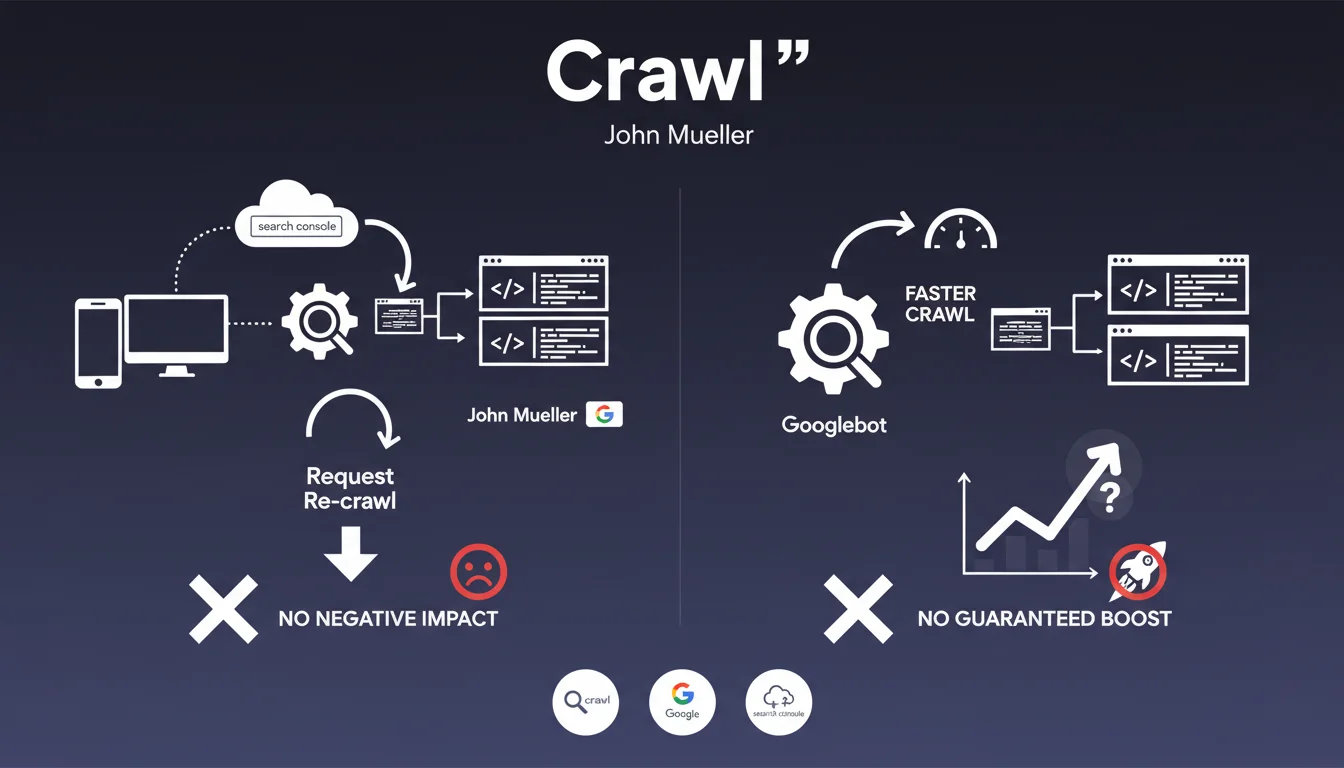
Quel est le comportement standard de Googlebot lors du crawl initial ?
Googlebot suit une logique pragmatique : il commence généralement son exploration par la première page qu'il découvre. Dans la plupart des cas, il s'agit effectivement de la page d'accueil, simplement parce que c'est elle qui reçoit le plus de liens externes.
Cependant, cette règle n'est pas absolue. Si Googlebot découvre votre site via un lien direct vers une page interne, c'est par cette page qu'il débutera son exploration. Le robot ne fait pas de distinction hiérarchique entre les pages lors de sa découverte initiale.
Comment Googlebot découvre-t-il les nouvelles pages d'un site ?
Le processus de découverte repose sur plusieurs mécanismes. Les liens entrants externes constituent la principale porte d'entrée, qu'ils pointent vers la homepage ou ailleurs.
Le fichier sitemap.xml joue également un rôle crucial en signalant directement les URLs à explorer. Les liens trouvés sur les pages déjà crawlées permettent ensuite à Googlebot de naviguer dans l'architecture du site.
Pourquoi cette flexibilité dans le point de départ du crawl ?
Google optimise constamment l'efficacité de son budget de crawl. Le robot est programmé pour suivre le chemin le plus naturel et économique lors de la découverte d'un nouveau site.
- Le point d'entrée dépend de la source de découverte (backlink, sitemap, suggestion d'URL)
- La page d'accueil n'a pas de priorité technique intrinsèque dans l'algorithme de crawl
- Googlebot privilégie l'efficacité du parcours plutôt qu'une hiérarchie prédéfinie
- Les pages avec plus de liens entrants sont statistiquement découvertes en premier
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Cette affirmation de John Mueller reflète parfaitement ce que nous observons dans les logs serveur de nos audits. Les sites lancés avec une stratégie de netlinking ciblant des pages profondes voient effectivement ces pages crawlées en priorité.
Les données de crawl montrent que sur les sites e-commerce avec des liens directs vers des fiches produits populaires, Googlebot commence fréquemment par ces pages plutôt que par la homepage. C'est une réalité documentée dans nos analyses de log files.
Quelles nuances importantes faut-il apporter à cette règle ?
Bien que le principe soit clair, le comportement post-découverte diffère du crawl initial. Une fois le site connu, Google développe une compréhension de l'architecture globale et ajuste ses priorités de crawl.
La homepage conserve généralement un crawl régulier et fréquent car elle accumule naturellement du PageRank interne et externe. Les pages importantes bénéficient d'un taux de revisite proportionnel à leur autorité et leur fréquence de mise à jour.
Dans quels cas cette logique peut-elle poser problème ?
Sur les sites avec une architecture mal conçue, Googlebot peut découvrir une page interne orpheline ou mal liée. Il risque alors de peiner à explorer l'ensemble du site par manque de maillage interne efficace.
Les sites avec un sitemap incomplet ou inexistant qui reçoivent leurs premiers liens vers des pages secondaires peuvent voir leur crawl initial incomplet. La découvrabilité des contenus devient alors problématique.
Impact pratique et recommandations
Que faut-il optimiser concrètement pour le crawl initial ?
L'essentiel est d'assurer une découvrabilité maximale dès le lancement du site. Soumettez votre sitemap.xml via la Search Console avant même d'obtenir vos premiers backlinks.
Construisez une architecture en silo cohérente où chaque page importante est accessible en 3 clics maximum depuis n'importe quel point d'entrée. Le maillage interne doit permettre à Googlebot de naviguer efficacement quelle que soit sa porte d'entrée.
Privilégiez les liens contextuels profonds dans votre stratégie de netlinking plutôt que de concentrer tous les backlinks sur la homepage. Cette approche favorise un crawl plus complet et une meilleure distribution du PageRank.
Quelles erreurs courantes faut-il absolument éviter ?
Ne créez jamais de pages orphelines sans aucun lien interne. Si Googlebot les découvre en premier, il ne pourra pas explorer le reste de votre site efficacement.
Évitez de bloquer des sections entières dans le robots.txt lors du lancement. Une sur-restriction du crawl peut empêcher l'indexation de contenus pourtant essentiels.
- Ne pas lancer un site sans sitemap.xml correctement configuré et soumis
- Ne pas négliger le maillage interne sous prétexte que les backlinks pointent vers la homepage
- Ne pas créer de silos hermétiques sans passerelles entre les sections du site
- Ne pas oublier de monitorer les premiers crawls via les logs serveur
Comment vérifier que votre site est optimisé pour tout point d'entrée ?
Analysez vos logs serveur pour identifier les premières pages crawlées par Googlebot. Utilisez la Search Console pour vérifier que toutes vos URLs importantes sont découvertes et indexées rapidement.
Testez votre navigation interne en simulant différents points d'entrée : pouvez-vous atteindre toutes les pages stratégiques en 3 clics depuis n'importe quelle page ? Vérifiez la profondeur de crawl dans vos analytics.
Auditez régulièrement votre budget de crawl pour vous assurer qu'il est utilisé efficacement sur vos contenus prioritaires plutôt que gaspillé sur des pages de faible valeur.
💬 Commentaires (0)
Soyez le premier à commenter.