Declaration officielle
Autres déclarations de cette vidéo 2 ▾
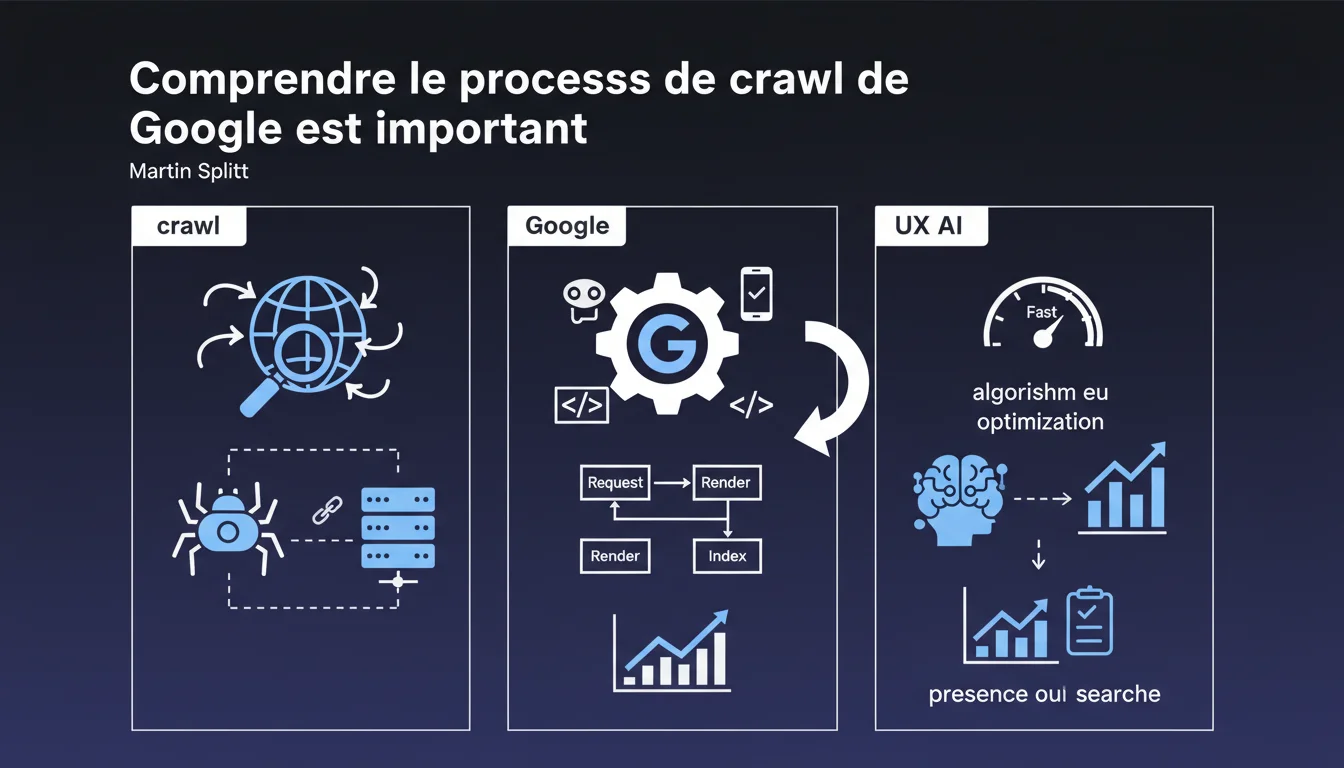
Google insiste sur l'importance de comprendre le processus de crawl de Googlebot pour optimiser sa visibilité dans les résultats de recherche. Cette déclaration rappelle que la qualité du crawl conditionne directement l'indexation et le positionnement. Sans une maîtrise fine du comportement de Googlebot sur votre site, vous laissez sur la table des opportunités de référencement.
Ce qu'il faut comprendre
Que signifie vraiment « comprendre le processus de crawl » ?
Google ne parle pas ici de simplement savoir que Googlebot existe ou qu'il passe de temps en temps sur votre site. La recommandation porte sur une compréhension opérationnelle : comment le robot priorise les pages, quels signaux influencent sa fréquence de passage, comment il gère les ressources allouées à votre domaine.
Concrètement, cela implique de monitorer les logs serveur, d'analyser les comportements de crawl dans la Search Console, et de détecter les blocages techniques qui empêchent Googlebot d'accéder à certaines sections stratégiques. Sans cette vision, vous pilotez à l'aveugle.
Pourquoi Google insiste-t-il sur ce point maintenant ?
Cette déclaration n'arrive pas par hasard. Avec la complexité croissante des architectures web — JavaScript lourd, SPAs, sites headless — les problèmes de crawl se sont multipliés. Beaucoup de sites modernes génèrent du contenu côté client que Googlebot peine à découvrir ou traite avec retard.
Par ailleurs, Google a affiné son crawl budget : il n'explore pas tout, tout le temps. Comprendre comment il répartit ses ressources devient un avantage compétitif direct, surtout sur les gros sites qui publient du contenu en continu.
Quels sont les signaux qui influencent le comportement de Googlebot ?
Plusieurs facteurs déterminent comment Googlebot explore votre site. La popularité des pages — mesurée par les liens internes et externes — joue un rôle clé. Une page très liée sera crawlée plus fréquemment qu'une page orpheline.
La fraîcheur du contenu compte aussi : un site qui publie quotidiennement recevra plus de visites qu'un site statique. Enfin, les performances serveur et la vitesse de réponse conditionnent le nombre de requêtes que Googlebot accepte d'envoyer sans risquer de surcharger votre infrastructure.
- Priorisation basée sur la popularité : les pages avec plus de backlinks et de liens internes sont crawlées en priorité
- Fréquence de mise à jour : les sites dynamiques bénéficient de passages plus réguliers
- Performances techniques : temps de réponse serveur, erreurs HTTP, timeouts influencent directement le crawl budget
- Architecture d'information : la profondeur des pages et la qualité du maillage interne déterminent la découvrabilité
- Fichiers de contrôle : robots.txt, sitemaps XML, directives meta robots orientent le comportement du robot
Avis d'un expert SEO
Cette recommandation reflète-t-elle vraiment les enjeux terrain ?
Oui, et c'est même un euphémisme. Sur le terrain, une majorité de sites perdent du potentiel SEO à cause de problèmes de crawl non détectés. Pages stratégiques non explorées, facettes e-commerce crawlées inutilement, contenus dupliqués indexés par erreur — la liste est longue.
L'analyse des logs montre régulièrement que Googlebot passe 70% de son temps sur des pages sans valeur SEO (filtres, paginations obsolètes, URLs paramétrées) alors que des contenus prioritaires ne sont visités qu'une fois par mois. Comprendre le crawl, c'est corriger ces déséquilibres.
Quelles nuances faut-il apporter à cette déclaration ?
Google parle de « comprendre », mais ne fournit pas de méthodologie précise. [A vérifier] La Search Console donne des indicateurs partiels — pages crawlées, erreurs HTTP — mais reste muette sur le détail du crawl budget alloué, la fréquence réelle par typologie de page, ou les critères exacts de priorisation.
Pour une vraie compréhension, il faut croiser Search Console, analyse des logs serveur bruts, et outils tiers. Ne vous contentez pas des dashboards Google : ils masquent une partie des comportements réels de Googlebot.
Autre point : cette recommandation est particulièrement critique pour les gros sites (e-commerce, médias, annuaires). Sur un site vitrine de 20 pages, le crawl budget n'est pas un enjeu. Sur un catalogue de 500 000 produits, c'est une variable stratégique de premier ordre.
Dans quels cas cette règle ne s'applique-t-elle pas pleinement ?
Les petits sites à faible fréquence de publication n'ont pas besoin d'optimiser le crawl au millimètre. Si vous avez 50 pages et que vous publiez un article par mois, Googlebot passera de toute façon régulièrement sans que vous ayez à intervenir.
En revanche, dès que vous franchissez un certain volume — plusieurs milliers de pages, ou une production quotidienne — le pilotage du crawl devient un levier de performance. Ignorer ce sujet sur un site e-commerce, c'est laisser vos nouveaux produits mettre des semaines à être indexés.
Impact pratique et recommandations
Que faut-il faire concrètement pour maîtriser le crawl ?
D'abord, analysez vos logs serveur. Identifiez quelles pages Googlebot visite réellement, à quelle fréquence, et combien de temps il passe sur chaque section. Comparez cela à vos priorités business : vos pages stratégiques sont-elles suffisamment crawlées ?
Ensuite, optimisez votre maillage interne. Les pages importantes doivent être accessibles en 3 clics maximum depuis la home, et recevoir des liens depuis des pages déjà bien crawlées. Réduisez la profondeur des contenus prioritaires.
Nettoyez votre robots.txt et votre sitemap XML. Bloquez les sections inutiles (recherche interne, filtres redondants), et ne soumettez dans le sitemap que les URLs à forte valeur ajoutée. Un sitemap de 100 000 URLs dont 80% sont du bruit dilue l'attention de Googlebot.
Quelles erreurs éviter absolument ?
Ne bloquez jamais par erreur des ressources critiques (CSS, JS nécessaires au rendu) dans le robots.txt. Googlebot a besoin de ces fichiers pour comprendre le contenu rendu côté client. Une règle trop restrictive peut rendre vos pages invisibles.
Évitez aussi les chaînes de redirections longues et les boucles. Googlebot abandonne souvent après 3-4 redirections, ce qui fait perdre le crawl de la page finale. Corrigez vos 301 en direct vers la destination finale.
Enfin, ne surchargez pas votre site de contenus dupliqués non canonicalisés. Si Googlebot passe son temps à crawler des variantes identiques, il néglige les pages uniques. Utilisez les balises canonical de manière stricte.
Comment vérifier que mon site est correctement configuré ?
Consultez le rapport de couverture dans la Search Console : vérifiez qu'il n'y a pas de pages importantes exclues ou bloquées par erreur. Regardez aussi le rapport « Statistiques d'exploration » pour détecter des pics d'erreurs ou des ralentissements.
Auditez régulièrement vos fichiers robots.txt et sitemaps avec des outils comme Screaming Frog ou Oncrawl. Croisez avec les logs pour voir si Googlebot respecte vos directives ou s'il explore des zones non souhaitées.
Mesurez le délai moyen d'indexation de vos nouvelles pages. Si un produit ou un article met plus d'une semaine à apparaître dans l'index, c'est un signal que votre crawl n'est pas optimal.
- Analyser les logs serveur pour identifier les patterns de crawl réels
- Optimiser le maillage interne pour faciliter la découverte des pages prioritaires
- Nettoyer le robots.txt : bloquer uniquement les sections inutiles
- Soumettre un sitemap XML ciblé, sans URLs de faible valeur
- Corriger les chaînes de redirections et éliminer les boucles
- Canonicaliser strictement les contenus dupliqués
- Surveiller le rapport de couverture et les statistiques d'exploration dans Search Console
- Mesurer le délai d'indexation des nouveaux contenus
- Vérifier que les ressources JS/CSS critiques ne sont pas bloquées
❓ Questions frequentes
Qu'est-ce que le crawl budget et comment l'optimiser ?
Comment savoir si Googlebot crawle efficacement mon site ?
Faut-il analyser les logs serveur ou la Search Console suffit-elle ?
Quel impact le JavaScript a-t-il sur le crawl de Googlebot ?
Les sitemaps XML influencent-ils vraiment le crawl ?
🎥 De la même vidéo 2
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/06/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.