Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Que se passe-t-il réellement quand Google vous inflige une action manuelle ?
- □ Un site hors ligne peut-il vraiment détruire votre trafic de toutes les sources (et pas seulement Google) ?
- □ Les Core Updates provoquent-elles vraiment des changements progressifs plutôt que des chutes brutales ?
- □ Pourquoi analyser 16 mois de données Search Console lors d'une chute de trafic ?
- □ Comment analyser correctement une baisse de trafic SEO sans se tromper de diagnostic ?
- □ Faut-il vraiment analyser tous les onglets de Search Console pour diagnostiquer une baisse de trafic ?
- □ Pourquoi devriez-vous arrêter d'analyser votre trafic SEO de manière globale ?
- □ Pourquoi Google ajoute-t-il des annotations dans Search Console et comment les interpréter ?
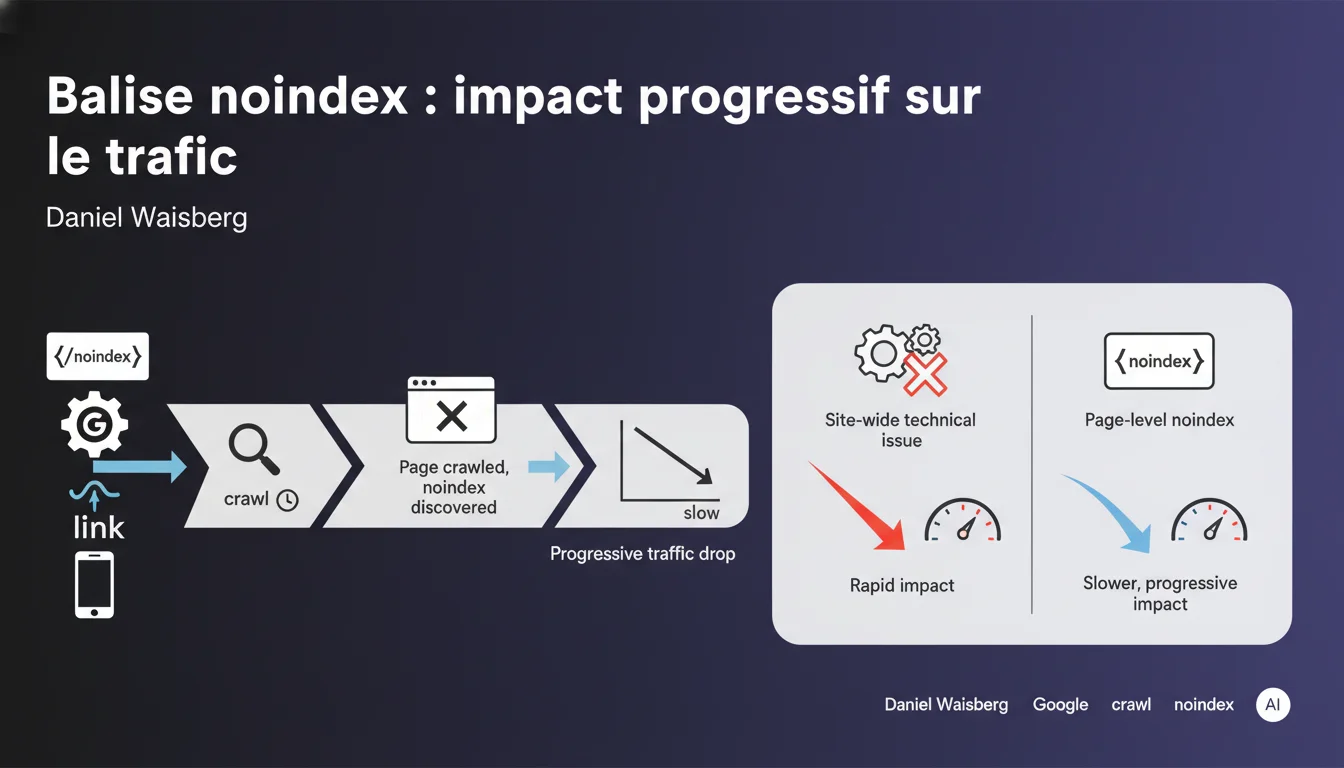
Une balise noindex non intentionnelle déclenche une chute de trafic graduelle, plus lente qu'un problème technique global. La raison ? Google doit d'abord recrawler chaque page concernée pour détecter la directive. Ce délai de découverte retarde l'impact visible, contrairement à un blocage serveur qui frappe instantanément tout le site.
Ce qu'il faut comprendre
Pourquoi la baisse de trafic est-elle progressive et non immédiate ?
Contrairement à un blocage robots.txt ou une erreur serveur qui affecte l'ensemble du site instantanément, une balise noindex fonctionne au niveau de chaque page individuelle. Google doit recrawler chaque URL pour détecter la directive avant de la retirer de l'index.
Si votre site compte 10 000 pages et que Googlebot en crawle 500 par jour, il faudra 20 jours avant que toutes les pages soient vérifiées. Durant cette période, les pages non encore recrawlées restent indexées et génèrent du trafic. La baisse s'installe donc par vagues, au rythme du crawl.
En quoi ce comportement diffère-t-il d'un problème technique global ?
Un blocage au niveau serveur (503, robots.txt, pare-feu) empêche immédiatement l'accès de Googlebot à toutes les ressources concernées. L'impact sur le trafic est brutal et visible en 24-48h.
Avec une balise noindex, chaque page suit son propre calendrier de recrawl. Les URLs fréquemment visitées par Googlebot disparaissent rapidement, tandis que les pages orphelines ou profondes peuvent rester indexées plusieurs semaines. Cette désynchronisation crée une courbe de décroissance étalée.
Quels facteurs influencent la vitesse de cette baisse ?
Plusieurs variables déterminent la rapidité avec laquelle Google détectera la balise noindex sur vos pages :
- Fréquence de crawl : un site crawlé quotidiennement verra l'impact en quelques jours, contre plusieurs semaines pour un site à faible crawl budget
- Popularité des pages : les URLs à fort trafic sont recrawlées plus souvent et disparaîtront en premier
- Profondeur de navigation : les pages enterrées à 5+ clics de la homepage mettent plus de temps à être découvertes
- Signal via sitemap : envoyer un sitemap avec lastmod récent accélère le recrawl
- Cache serveur/CDN : si Google crawle une version mise en cache sans la balise, le délai s'allonge
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. Les audits post-migration révèlent régulièrement ce pattern : un développeur ajoute une balise noindex sur un template, et le client signale une hémorragie de trafic 2-3 semaines plus tard. Pas immédiatement. Le temps que Google recrawle la masse critique de pages concernées.
Ce délai crée un piège sournois — quand le problème devient visible dans Analytics, des centaines de pages sont déjà désindexées. Le rollback ne suffit pas : il faut attendre un nouveau cycle de recrawl complet pour récupérer les positions perdues. Entre-temps, certains concurrents ont pris la place.
Quelles nuances faut-il apporter à cette règle ?
Daniel Waisberg parle d'un impact "plus lent" sans donner de référentiel temporel précis. Concrètement ? Sur un site e-commerce à 50 000 produits, j'ai déjà observé une chute étalée sur 6 semaines. Sur un blog de 200 articles crawlé quotidiennement, l'effondrement était visible en 5 jours. [À vérifier] : Google ne communique pas de métriques chiffrées sur la cinétique type.
Autre point — la déclaration suppose un crawl "normal". Mais si vous forcez un recrawl massif via Search Console (Inspection d'URL) ou un sitemap XML mis à jour frénétiquement, vous pouvez accélérer artificiellement la désindexation. L'inverse est vrai : un site avec crawl budget épuisé peut garder des pages noindex dans l'index pendant des mois.
Dans quels cas cette règle ne s'applique-t-elle pas strictement ?
Si la balise noindex est ajoutée via JavaScript côté client et que Google n'exécute pas le JS lors du premier crawl, la directive peut être totalement ignorée. Certains bots tiers ne rendent jamais le JS — ces pages restent indexées indéfiniment ailleurs que sur Google.
Autre exception — les pages avec très forte autorité externe (backlinks puissants) peuvent parfois rester en cache Google plusieurs semaines après détection du noindex, le temps que l'algorithme arbitre entre signaux contradictoires. Mais c'est marginal.
Impact pratique et recommandations
Comment détecter rapidement une balise noindex non intentionnelle ?
Le réflexe : surveillez la métrique "Pages indexées" dans Google Search Console. Une chute progressive sans explication (pas de pénalité, pas de changement d'archi) signale souvent un noindex parasite. Creusez les rapports de couverture pour identifier les URLs exclues avec raison "Exclue par la balise noindex".
Automatisez la détection via un crawl Screaming Frog hebdomadaire avec alerte si le nombre de pages noindex augmente brutalement. Comparez avec un crawl de référence. Si 500 nouvelles pages passent en noindex du jour au lendemain après un déploiement, vous avez 48h pour corriger avant que Google ne les découvre massivement.
Que faire si le mal est déjà fait ?
Retirez immédiatement la balise noindex, mais ne vous attendez pas à un rebond instantané. Google doit recrawler les URLs nettoyées pour les réintégrer. Accélérez le processus en :
- Soumettant un sitemap XML frais avec lastmod à jour pour forcer un recrawl prioritaire
- Utilisant l'outil Inspection d'URL dans Search Console sur les pages stratégiques (limité à quelques dizaines par jour)
- Renforçant temporairement le maillage interne vers les pages concernées pour augmenter leur crawl rate
- Évitant de bloquer le crawl via robots.txt ou rate limiting pendant la phase de récupération
Soyons honnêtes — même avec ces leviers, comptez 2 à 6 semaines pour retrouver les positions initiales. Certaines pages ne récupèreront jamais complètement si des concurrents ont comblé le vide entre-temps.
Quelles erreurs éviter pour prévenir ce scénario ?
Ne déployez jamais un changement de template global (header, footer) sans vérifier les directives d'indexation. Un CMS mal configuré peut injecter un noindex sur toutes les pages enfants d'une catégorie sans que vous le remarquiez dans le backoffice.
Testez sur un environnement de staging accessible à Googlebot (via Search Console) avant la mise en production. Crawlez cet environnement avec les mêmes outils que Google pour repérer les incohérences. Et documentez explicitement quelles sections du site doivent porter un noindex légitime (facettes, archives, pages de recherche interne).
❓ Questions frequentes
Combien de temps faut-il pour qu'une page avec balise noindex disparaisse de l'index Google ?
Peut-on accélérer la réindexation après avoir retiré une balise noindex ?
Une balise noindex ajoutée via JavaScript est-elle prise en compte par Google ?
Quelle différence entre un blocage robots.txt et une balise noindex en termes d'impact sur le trafic ?
Comment détecter automatiquement l'apparition de balises noindex non désirées ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.